[Project#11] DDPG 구현
[Project#] 시리즈는 프로젝트(Manipulator Continuous Control with Deep Reinforcement Learning) 제작 과정을 설명한다. 본 포스팅은 DDPG Agent 구현 과정에 대한 내용이다.
모든 내용은 이전 글과 이어진다. 이전 글을 읽어봤다고 가정한 후 글을 작성하였다. (이전 글 LINK)
1. DDPG_manipulator.py 생성
1.1. Actor 클래스
class Actor(nn.Module):
def __init__(
self,
state_size,
hidden_size,
action_size,
device
) -> None:
super(Actor, self).__init__()
self.device = device
self.fc_1 = nn.Linear(in_features=state_size, out_features=hidden_size)
self.fc_2 = nn.Linear(in_features=hidden_size, out_features=int(hidden_size / 2))
self.fc_3 = nn.Linear(in_features=int(hidden_size / 2), out_features=action_size)
for m in self.modules():
if isinstance(m, nn.Linear):
torch.nn.init.xavier_normal_(m.weight.data)
m.bias.data.fill_(0.01)
def forward(self, state):
x = F.relu(self.fc_1(state))
x = F.relu(self.fc_2(x))
action = F.tanh(self.fc_3(x))
return action
- 행동자(Actor)는 상태(state)를 입력으로 받아 행동(action)을 반환한다.
1.2. Critic 클래스
class Critic(nn.Module):
def __init__(
self,
state_size,
hidden_size,
action_size,
device
) -> None:
super(Critic, self).__init__()
self.device = device
self.state_fc_1 = nn.Linear(state_size, hidden_size)
self.state_fc_2 = nn.Linear(hidden_size, int(hidden_size / 2))
self.action_fc_1 = nn.Linear(action_size, int(hidden_size / 2))
self.add_fc_1 = nn.Linear(hidden_size, 1)
for m in self.modules():
if isinstance(m, nn.Linear):
torch.nn.init.xavier_normal_(m.weight.data)
m.bias.data.fill_(0.01)
def forward(self, state, action):
x_s = F.relu(self.state_fc_1(state))
x_s = F.relu(self.state_fc_2(x_s))
x_a = F.relu(self.action_fc_1(action))
x = torch.cat((x_s, x_a), dim=1)
x = F.tanh(self.add_fc_1(x))
return x
- 비평가(Critic)는 상태(state)와 행동(action), 둘 다 입력으로 받으며, Q_value를 반환한다.
- Critic을 비평가로 번역하는 것이 옳은지 모르겠다. 우선, 현재 상태(state)를 평가한다는 의미에서 비평가라는 단어를 선택하게 되었다.
1.3. OU_Noise 클래스
class OU_Noise():
def __init__(self, action_dim, mu=0.0, theta=0.15, max_sigma=0.1, min_sigma=0.1, decay_period=100000):
self.mu = mu
self.theta = theta
self.sigma = max_sigma
self.max_sigma = max_sigma
self.min_sigma = min_sigma
self.decay_period = decay_period
self.action_dim = action_dim
self.reset()
def reset(self):
self.state = np.ones(self.action_dim) * self.mu
def evolve_state(self):
x = self.state
dx = self.theta * (self.mu - x) + self.sigma * np.random.randn(self.action_dim)
self.state = x + dx
return self.state
def get_noise(self, t=0):
ou_state = self.evolve_state()
decaying = float(float(t) / self.decay_period)
self.sigma = max(self.sigma - (self.max_sigma - self.min_sigma) * min(1.0, decaying), self.min_sigma)
return ou_state
- 관성이 있는 물리적 제어 문제에서 탐색 효율성을 위한 시간적 상관 탐색을 생성하기 위해 Ornstein-Uhlenbeck 프로세스를 사용했다고 한다.
- 그러나 OU Noise를 사용한 명확한 이유를 아직 모르겠다.
1.4. Replay_Buffer 클래스
class Replay_Buffer():
def __init__(self, max_size):
self.buffer = deque(maxlen=max_size)
def push(self, state, action, reward, next_state):
experience = (state, action, np.array([reward]), next_state)
self.buffer.append(experience)
def sample(self, batch_size):
state_batch = []
action_batch = []
reward_batch = []
next_state_batch = []
batch = random.sample(self.buffer, batch_size)
for experience in batch:
state, action, reward, next_state = experience
state_batch.append(state)
action_batch.append(action)
reward_batch.append(reward)
next_state_batch.append(next_state)
return state_batch, action_batch, reward_batch, next_state_batch
def __len__(self):
return len(self.buffer)
- 상태(state), 행동(acition), 보상(reward), 다음 상태(next_state)를 계속해서 저장할 수 있는 버퍼 클래스를 생성하였다.
- replay_buffer의 가장 큰 장점은 i.i.d 형성이라고 생각한다. 또한, 너무 과거의 상태를 학습하지 않기 때문에 잘못된 방향으로 학습하는 경향을 감소시킬 수 있는 것이라 생각한다.
1.5. Agent 클래스
class Agent():
def __init__(
self,
hidden_size=256,
actor_learning_rate=1e-4,
critic_learning_rate=1e-4,
gamma=0.99,
tau=0.9999,
tau_actor=9e-4,
tau_critic=1e-4,
max_memory_size=50000,
ou_noise=False,
n_learn=16,
device='cpu'
):
self.state_size = 10
self.action_size = 6
self.gamma = gamma
self.tau = tau
self.tau_actor = tau_actor
self.tau_critic = tau_critic
self.t_step = 0
self.ou_noise = ou_noise
self.n_learn = n_learn
self.device = device
if self.device == 'cuda':
self.gamma = torch.FloatTensor([gamma]).to(self.device)
self.tau = torch.FloatTensor([tau]).to(self.device)
self.tau_actor = torch.FloatTensor([tau_actor]).to(self.device)
self.tau_critic = torch.FloatTensor([tau_critic]).to(self.device)
print(f"[device: {self.device}]")
# Initialization of the networks
self.actor = Actor(self.state_size, hidden_size, self.action_size, self.device) # main network Actor
self.critic = Critic(self.state_size, hidden_size, self.action_size, self.device) # main network Critic
self.actor_target = Actor(self.state_size, hidden_size, self.action_size, self.device)
self.critic_target = Critic(self.state_size, hidden_size, self.action_size, self.device)
self.actor = self.actor.to(self.device)
self.critic = self.critic.to(self.device)
self.actor_target = self.actor_target.to(self.device)
self.critic_target = self.critic_target.to(self.device)
# print("actor:", self.actor.is_cuda())
# print("critic:", self.critic.is_cuda())
# print("actor_target:", self.actor_target.is_cuda())
# print("critic_target:", self.critic_target.is_cuda())
# Initialization of the target networks as copies of the original networks
for target_param, param in zip(self.actor_target.parameters(), self.actor.parameters()):
target_param.data.copy_(param.data)
for target_param, param in zip(self.critic_target.parameters(), self.critic.parameters()):
target_param.data.copy_(param.data)
# Initialization memory
self.memory = Replay_Buffer(max_memory_size)
self.actor_optimizer = optim.AdamW(self.actor.parameters(), lr=actor_learning_rate)
self.critic_optimizer = optim.AdamW(self.critic.parameters(), lr=critic_learning_rate)
if self.ou_noise is True:
self.noise = OU_Noise(action_dim=self.action_size)
def load_weights(self, actor_path=None, critic_path=None):
if actor_path is None or critic_path is None: return
self.actor.load_state_dict(torch.load(actor_path))
self.critic.load_state_dict(torch.load(critic_path))
def get_action(self, state):
state_change = torch.tensor(state).float().to(self.device)
print(f"{state_change[1].cpu().numpy():.10}", state_change.dtype)
# print(state_change, state_change.dtype)
action = self.actor.forward(state_change)
if self.ou_noise is True:
noise = torch.from_numpy(copy.deepcopy(self.noise.get_noise(self.t_step))).to(self.device)
action = torch.clamp(torch.add(action, noise), -3.14159, 3.14159).to(self.device)
action = action.detach().cpu().numpy()
float_action = []
for float64_action in action:
float_action.append(float64_action.item())
return float_action
def step_training(self, batch_size):
self.t_step = self.t_step + 1
if self.memory.__len__() > batch_size:
for _ in range(self.n_learn):
self.learn_step(batch_size)
if self.device == 'cuda':
return self.actor_loss.detach().cpu().numpy(), self.critic_loss.detach().cpu().numpy()
else:
return self.actor_loss.detach().numpy(), self.critic_loss.detach().numpy()
return None, None
def learn_step(self, batch_size):
state, action, reward, next_state = self.memory.sample(batch_size)
state = np.array(state)
action = np.array(action)
reward = np.array(reward)
next_state = np.array(next_state)
state = torch.FloatTensor(state).to(self.device)
action = torch.FloatTensor(action).to(self.device)
reward = torch.FloatTensor(reward).to(self.device)
next_state = torch.FloatTensor(next_state).to(self.device)
Q_value = self.critic.forward(state, action)
next_action = self.actor_target.forward(next_state)
next_Q_value = self.critic_target.forward(next_state, next_action)
target_Q_value = reward + self.gamma * next_Q_value
loss = nn.MSELoss()
self.critic_loss = loss(Q_value, target_Q_value)
self.actor_loss = - self.critic.forward(state, self.actor.forward(state)).mean()
self.actor.zero_grad()
self.actor_loss.backward()
self.actor_optimizer.step()
self.critic.zero_grad()
self.critic_loss.backward()
self.critic_optimizer.step()
for target_param, param in zip(self.actor_target.parameters(), self.actor.parameters()):
target_param.data.copy_(param.data * self.tau_actor + target_param.data * (1.0 - self.tau))
for target_param, param in zip(self.critic_target.parameters(), self.critic.parameters()):
target_param.data.copy_(param.data * self.tau_critic + target_param.data * (1.0 - self.tau))
def save_model(self, save_path, file_name=None):
if file_name is not None:
torch.save(self.actor.state_dict(), f"{save_path}/actor_{file_name}.pt")
torch.save(self.critic.state_dict(), f"{save_path}/critic_{file_name}.pt")
else:
torch.save(self.actor.state_dict(), f"{save_path}/actor.pt")
torch.save(self.critic.state_dict(), f"{save_path}/critic.pt")
2. main_rl_environment.py 수정
2.1. get_space(state_space_funct) 함수 수정
def get_space(self, step=0):
try:
reward = self.calculate_reward_funct(step)
state = [
self.goal_0,
self.joint_1_pos, self.joint_2_pos, self.joint_3_pos, self.joint_4_pos, self.joint_5_pos, self.joint_6_pos,
self.robot_x, self.robot_y, self.robot_z
]
except:
self.get_logger().info('-------node not ready yet, Still getting values------------------')
return
else:
return state, reward
- 상태(state)는 현재 골 정보(True/False), 각 관절의 각도, end_point의 좌표를 포함한다.
2.2. calculate_reward_funct 함수 수정
def calculate_reward_funct(self, step=0):
try:
robot_end_position = np.array((self.robot_x, self.robot_y, self.robot_z))
target_point_position_0 = np.array((self.pos_sphere_0_x, self.pos_sphere_0_y, self.pos_sphere_0_z))
reward_0 = 0
except:
self.get_logger().info('could not calculate the distance yet, trying again...')
return
else:
distance_0 = np.linalg.norm(robot_end_position - target_point_position_0)
reward_d = - 0.1 * (distance_0**np.e)
if reward_d < -5: reward_d = -5
if distance_0 < 0.05 and step > 3:
self.get_logger().info('Goal Reached')
self.goal_0 = True
else:
self.goal_0 = False
if self.goal_0 is True: reward_0 = 5
return reward_d + reward_0
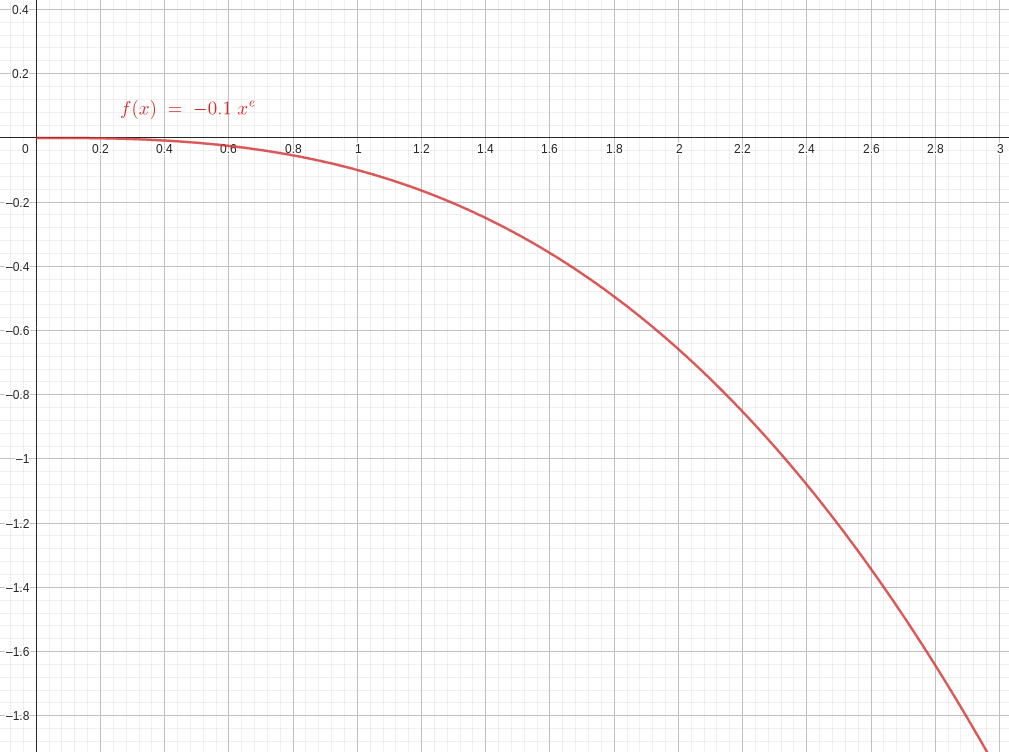
- 총 보상은 2가지 보상의 합으로 설정하였다.
-
첫 번째 보상은 목표지점과 end_point의 좌표가 멀수록 음수가 감소하도록 함수를 설정하였다.
→ $-0.1 * x^e$
- 두 번째 보상은 목표지점에 달성했는지 판단하여 +5 또는 0을 부여하였다.
3. train_ddpg.py 생성
from .DDPG_manipulator import Agent
from .main_rl_environment import MyRLEnvironmentNode
import matplotlib.pyplot as plt
import numpy as np
import time
import datetime
import random
import rclpy
def main(args=None):
rclpy.init(args=args)
env = MyRLEnvironmentNode()
rclpy.spin_once(env)
try:
EPISODE = 25
EPISODE_STEP = 1000
batch_size = 256
save_dir = "/home/dndqodqks/ros2_ws/src/robotic_arm_environment/my_environment_pkg"
agent = Agent(ou_noise=True,
critic_learning_rate=0.00001,
actor_learning_rate=0.00001,
max_memory_size=1000000,
hidden_size=512,
device='cuda') # 4:26, 2:56
agent.load_weights(save_dir+"/model/actor_755_h_512_best.pt", save_dir+"/model/critic_755_h_512_best.pt")
rewards = []
actor_loss = []
critic_loss = []
avg_rewards = []
avg_actor_loss = []
avg_critic_loss = []
goal_time_step = []
total_start_time = time.time()
for episode in range(EPISODE):
episode_start_time = time.time()
env.reset_environment_request()
agent.noise.reset()
state, _ = env.get_space()
episode_reward = 0
episode_actor_loss = np.array([])
episode_critic_loss = np.array([])
for step in range(EPISODE_STEP):
print (f'----------------Episode:{episode+1} Step:{step+1}--------------------')
if state[1] < -1.570795 or state[1] > 1.570795:
state[1] = random.uniform( -1.570795, 1.570795)
action = agent.get_action(state)
env.action_step_service(action_values=action, second=0.0001)
new_state, reward = env.get_space(step)
agent.memory.push(state, action, reward, new_state)
actor_loss, critic_loss = agent.step_training(batch_size)
state = new_state
episode_reward += reward
if actor_loss is not None and critic_loss is not None:
episode_actor_loss += actor_loss
episode_critic_loss += critic_loss
goal_time_step.append(0)
if actor_loss is not None and critic_loss is not None:
print(f'Episode/step: {episode+1}/{step+1}\treward: {reward:.6f}\tactor_loss: {actor_loss:.6f}\tcritic_loss: {critic_loss:.6f}')
else:
print(f'Episode/step: {episode+1}/{step+1}\treward: {reward:.6f}\tactor_loss: {actor_loss}\tcritic_loss: {critic_loss}')
if new_state[0] == True:
# if done is TRUE means the end-effector reach to goal and environmet will reset
print ("----------------Goal Reach----------------")
print(f"episode: {episode+1}, step: {step+1} reward: {np.round(episode_reward, decimals=2)}, average _reward: {np.mean(rewards[-10:])}")
goal_time_step.append(step+1)
agent.save_model(save_dir+"/ckp", f"{episode}_{step}")
break
# now_time = time.time()
# if now_time - episode_start_time > 20:
# print("----------------Time Out----------------")
# break
rewards.append(episode_reward)
avg_rewards.append(np.mean(rewards[-10:]))
if actor_loss is not None and critic_loss is not None:
actor_loss = np.append(actor_loss, episode_actor_loss)
critic_loss = np.append(critic_loss, episode_critic_loss)
avg_actor_loss = np.append(avg_actor_loss, np.mean(actor_loss[-10:]))
avg_critic_loss = np.append(avg_critic_loss, np.mean(critic_loss[-10:]))
episode_end_time = time.time()
episode_sec = episode_end_time - episode_start_time
episode_time = str(datetime.timedelta(seconds=episode_sec)).split(".")[0]
print(f'Episode {episode+1} Ended')
print('Episode Time: ', episode_time)
agent.save_model(save_dir+"/model")
total_end_time = time.time()
total_sec = total_end_time - total_start_time
total_time = str(datetime.timedelta(seconds=total_sec)).split(".")[0]
print("Total num of episode completed, Exiting ....")
print("Total Time:", total_time)
now = datetime.datetime.now()
ep = [i for i in range(EPISODE)]
plt.figure(figsize=(15, 10))
plt.subplot(2, 2, 1)
plt.grid(True)
plt.plot(ep, avg_rewards, label='avg_reward')
plt.xlabel('Episode')
plt.ylabel('Reward')
plt.legend()
reward_txt_ndarray = np.loadtxt(save_dir+"/data/reward.txt", delimiter=' ')
avg_rewards = np.concatenate([reward_txt_ndarray, avg_rewards], 0)
np.savetxt(save_dir+"/data/reward.txt", avg_rewards, fmt="%.6e")
if actor_loss is not None and critic_loss is not None:
plt.subplot(2, 2, 2)
plt.grid(True)
plt.plot(range(len(avg_actor_loss)), avg_actor_loss, label='avg_actor_loss')
plt.xlabel('Episode')
plt.ylabel('Actor Loss')
plt.legend()
plt.subplot(2, 2, 3)
plt.grid(True)
plt.plot(range(len(avg_critic_loss)), avg_critic_loss, label='avg_critic_loss')
plt.xlabel('Episode')
plt.ylabel('Critic Loss')
plt.legend()
actor_loss_txt_ndarray = np.loadtxt(save_dir+"/data/actor_loss.txt", delimiter=' ')
avg_actor_loss = np.concatenate([actor_loss_txt_ndarray, avg_actor_loss], 0)
np.savetxt(save_dir+"/data/actor_loss.txt", avg_actor_loss, fmt="%.6e")
critic_loss_txt_ndarray = np.loadtxt(save_dir+"/data/critic_loss.txt", delimiter=' ')
avg_critic_loss = np.concatenate([critic_loss_txt_ndarray, avg_critic_loss], 0)
np.savetxt(save_dir+"/data/critic_loss.txt", avg_critic_loss, fmt="%.6e")
plt.subplot(2, 2, 4)
plt.grid(True)
plt.stem(range(len(goal_time_step)), goal_time_step, label='goal')
plt.xlabel('Time Step')
plt.ylabel('Goal')
plt.legend()
plt.savefig(f'{save_dir+"/image"}/ddpg_{now.year}_{now.month}_{now.day}_{now.hour}_{now.minute}_{now.second}.png', dpi=300, facecolor='#eeeeee', bbox_inches='tight')
except:
agent.save_model(save_dir+"/model")
print("try-except save model")
rclpy.shutdown()
if __name__ == '__main__':
main()
print("Train Completed!!!")
- 학습 이후 평균 reward, actor_loss, critic_loss를 확인할 수 있도록 그래프로 저장하였다.
3. 실행
# terminal 1
ros2 launch my_environment_pkg my_environment.launch.py
# terminal 2
ros2 run my_environment_pkg train_ddpg
4. 참고 문헌
- https://github.com/tomasvr/turtlebot3_drlnav/blob/main/src/turtlebot3_drl/turtlebot3_drl/drl_agent/ddpg.py
- https://jkros.org/xml/32212/32212.pdf
- https://soeren-kirchner.medium.com/deep-deterministic-policy-gradient-ddpg-with-and-without-ornstein-uhlenbeck-process-e6d272adfc3
- https://github.com/ghliu/pytorch-ddpg/tree/master