[Project#12] 급하다 급해 전시회 준비
[Project#] 시리즈는 프로젝트(Manipulator Continuous Control with Deep Reinforcement Learning) 제작 과정을 설명한다. 본 포스팅은 작품의 완성도를 위한 노력을 기록해보았다.
모든 내용은 이전 글과 이어진다. 이전 글을 읽어봤다고 가정한 후 글을 작성하였다. (이전 글 LINK)
- 전시회가 얼마 남지 않아 학습하는 과정을 짧게나마 기록하였다.
1. 테스트 학습
| episode | 50 |
|---|---|
| time step | 1000 |
| batch size | 256 |
| actor learning rate | 0.001 |
| critic learning rate | 0.001 |
| tau | 0.001 |
| buffer size | 1000000 |
| hideen size | 512 |
| reward function | $distance_0 < 0.05 \ and \ time_step > 3 \ = 20$ |
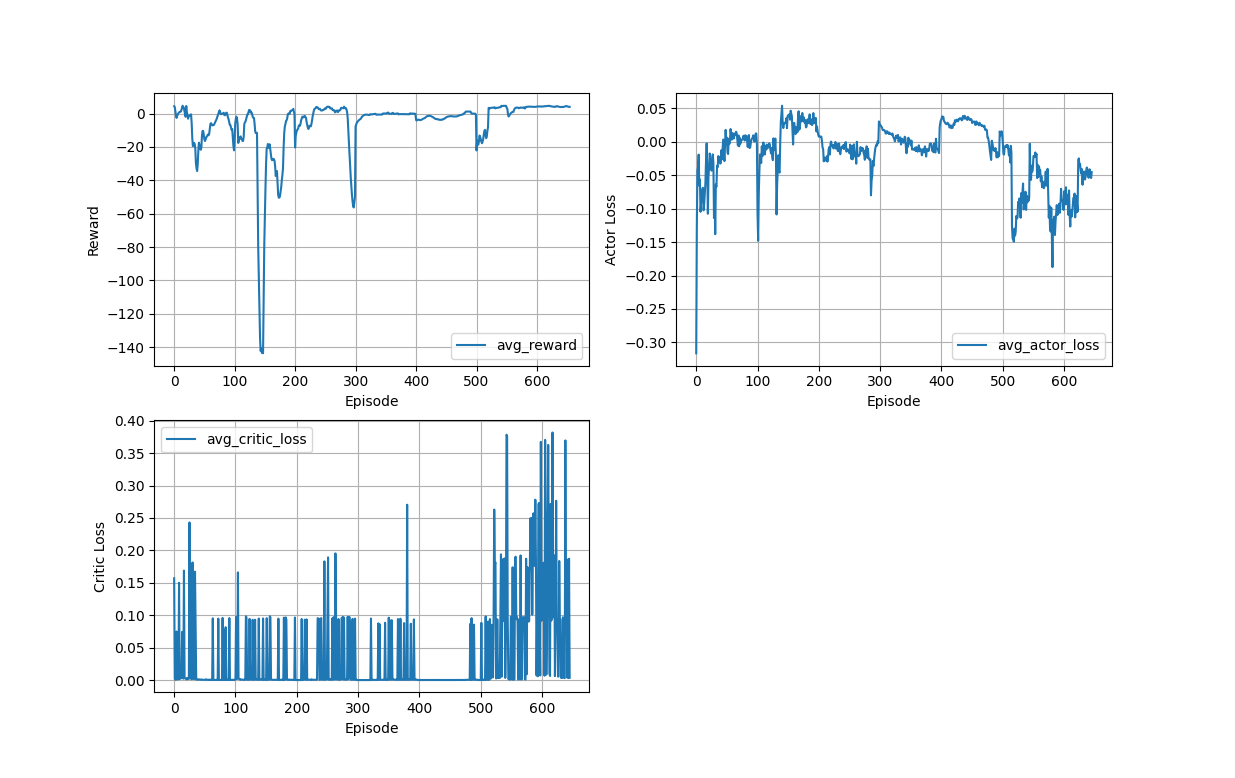
- loss 그래프만 보기엔 학습이 된 것 같지만 reward가 0이기에 전혀 학습되지 않았다.
2. time step 설정하기
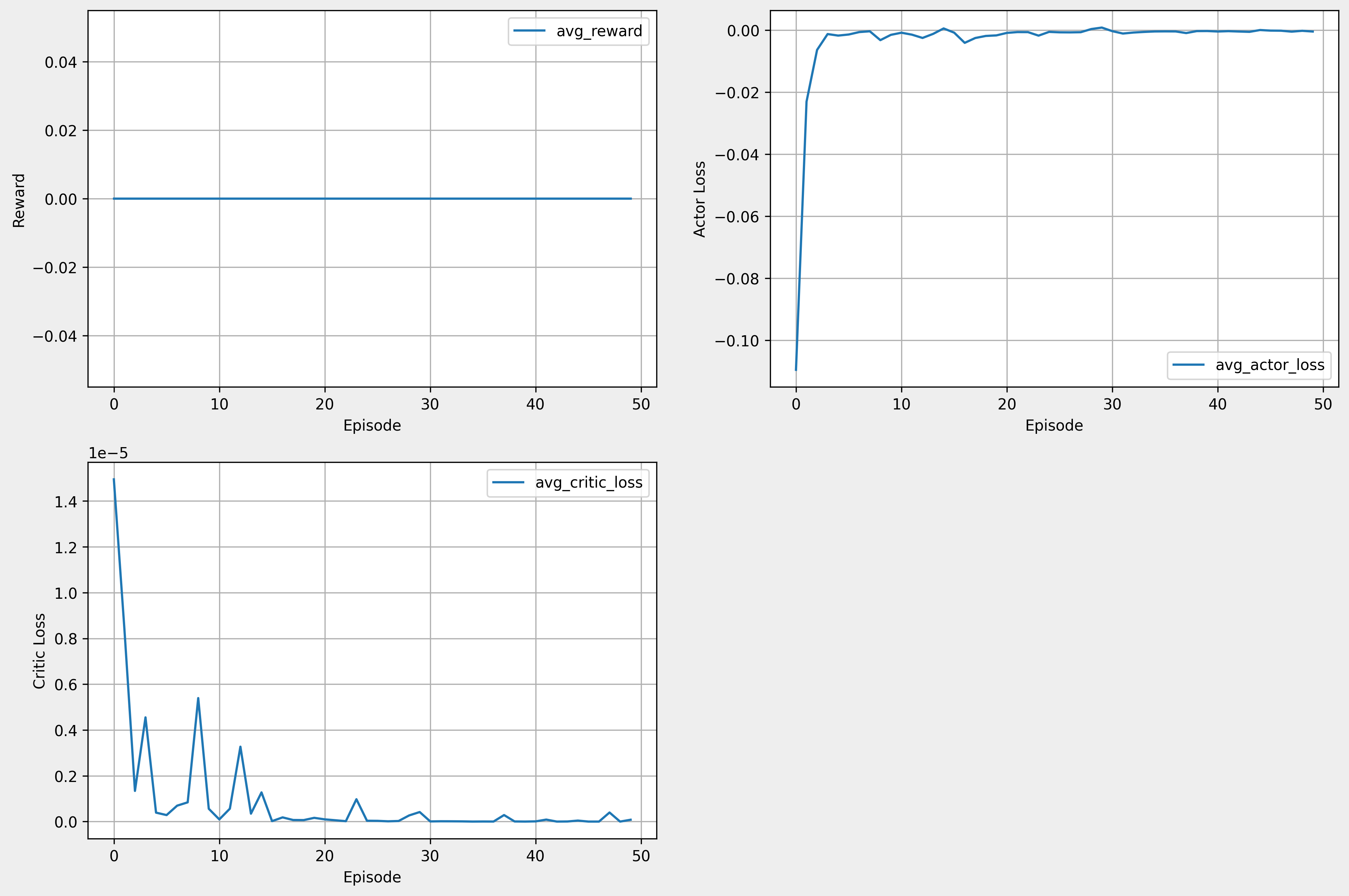
time step 500
time step 1000
- 테스트 학습 환경에서 time step만 변경하여 학습을 진행하였다.
- time step 500 보다 1000이 더 잘 되는 것을 확인하였다.
3. GPU를 활용하여 학습 진행(이전엔 CPU)
| episode | 50 |
|---|---|
| time step | 1000 |
| batch size | 256 |
| actor learning rate | 0.001 |
| critic learning rate | 0.001 |
| tau | 0.001 |
| buffer size | 1000000 |
| hideen size | 512 |
| 소요 시간(GPU 활용) | 5시간 56분 38초 |
reward_d = - 0.1 * (distance_0**np.e)
if reward_d < -5: reward_d = -5
if distance_0 < 0.05 and step > 3:
self.get_logger().info('Goal Reached')
self.goal_0 = True
else:
self.goal_0 = False
if self.goal_0 is True: reward_0 = 5
return reward_d + reward_0
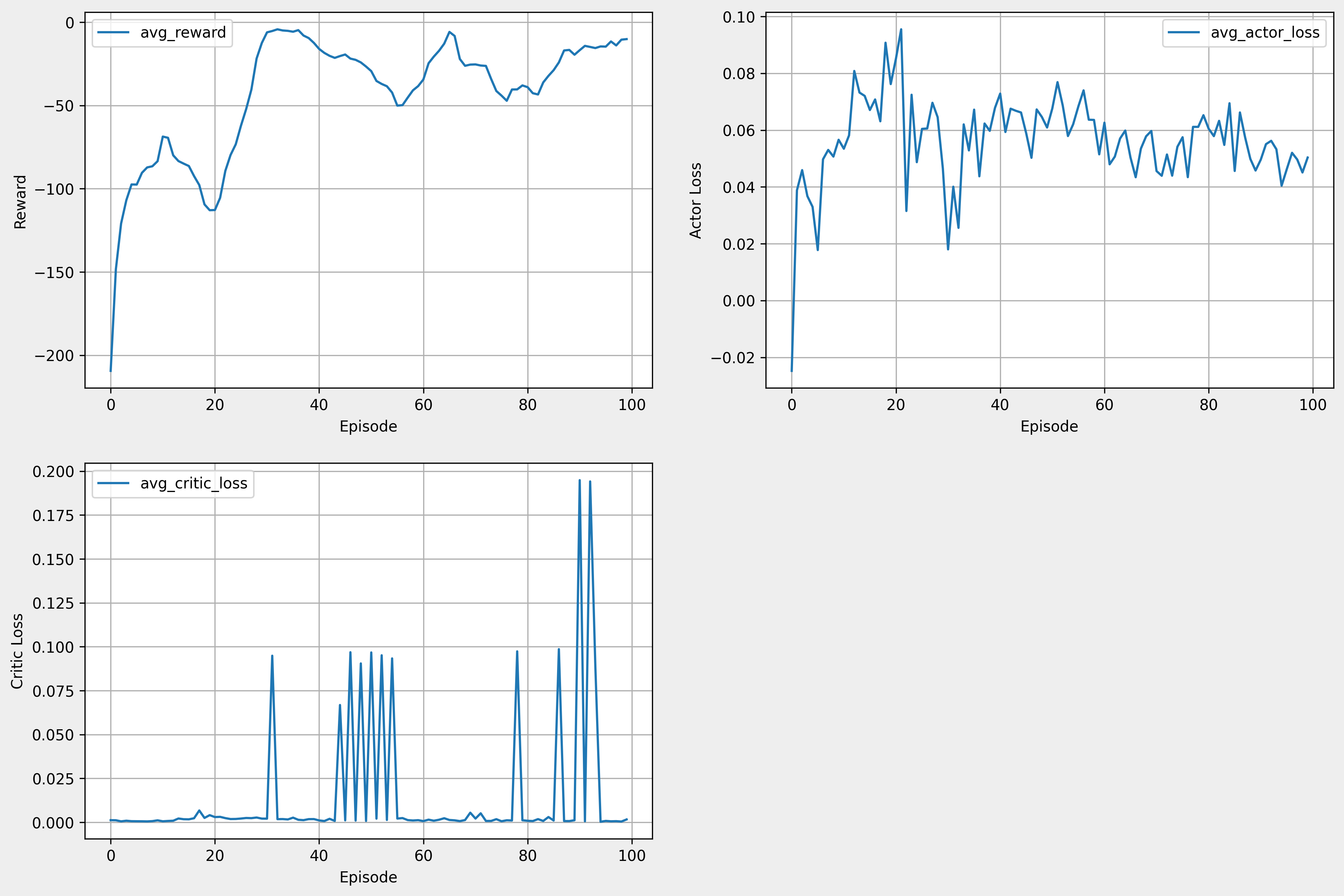
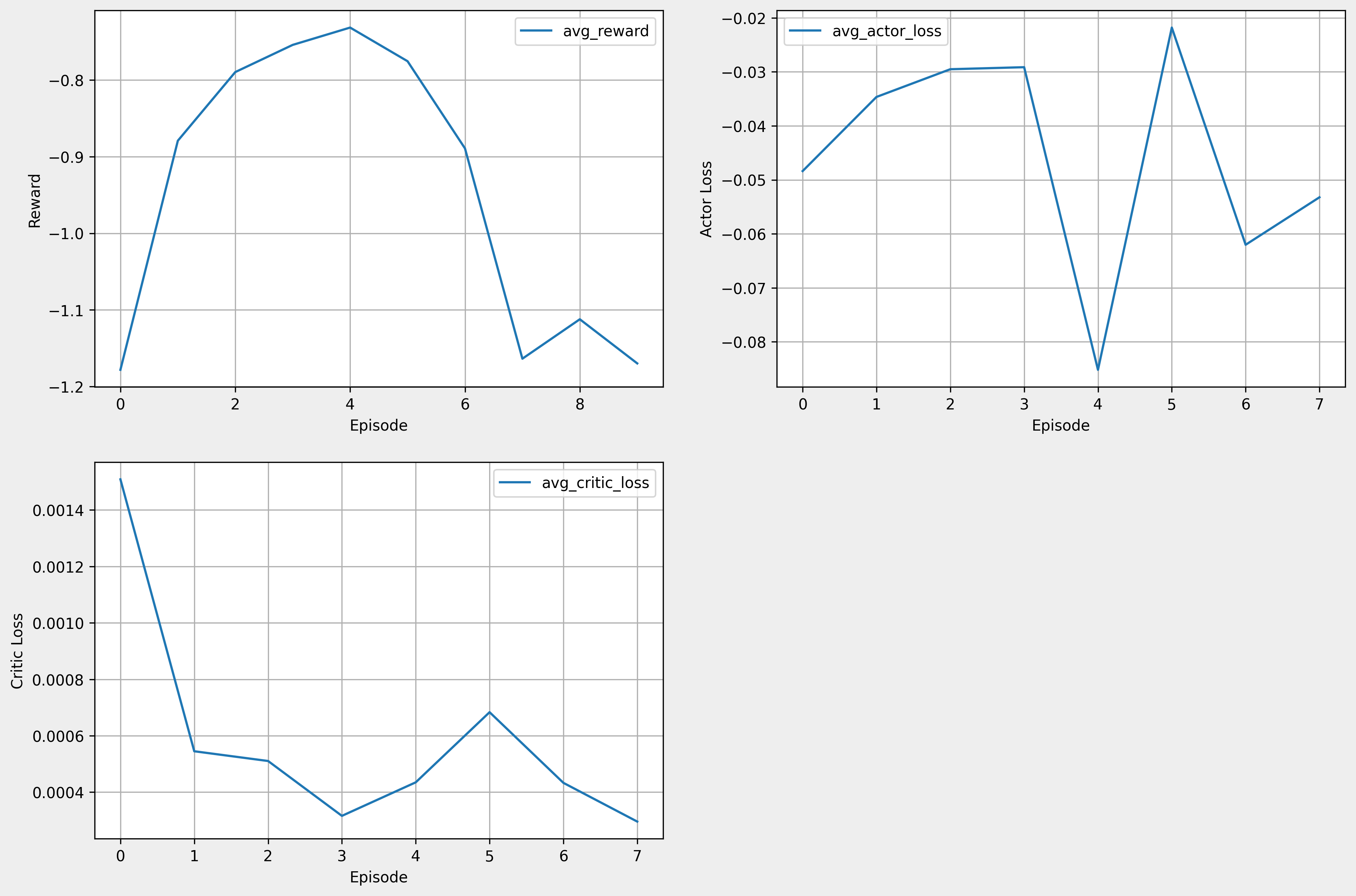
- cpu 연산 시 1 episode 당 4분 26초가 소요됐다. gpu 연산 시 1 episode 당 2분 56초가 소요됐다. 즉, gpu를 활용하는 것이 효과적이다.
- reward가 증가하는 추세를 보인다. 그러나 시뮬레이션에서 학습이 제대로 되진 않았다.
4. critic learning rate 변경 후 학습
| episode | 50 |
|---|---|
| time step | 1000 |
| batch size | 256 |
| actor learning rate | 0.001 |
| critic learning rate | 0.0001 |
| tau | 0.001 |
| buffer size | 1000000 |
| hideen size | 512 |
| 소요 시간(GPU 활용) | 3시간 8분 45초 |
reward_d = - distance_0 / 5
if distance_0 < 0.05 and step > 3:
self.get_logger().info('Goal Reached')
self.goal_0 = True
else:
self.goal_0 = False
if self.goal_0 is True: reward_0 = 20
return reward_d + reward_0
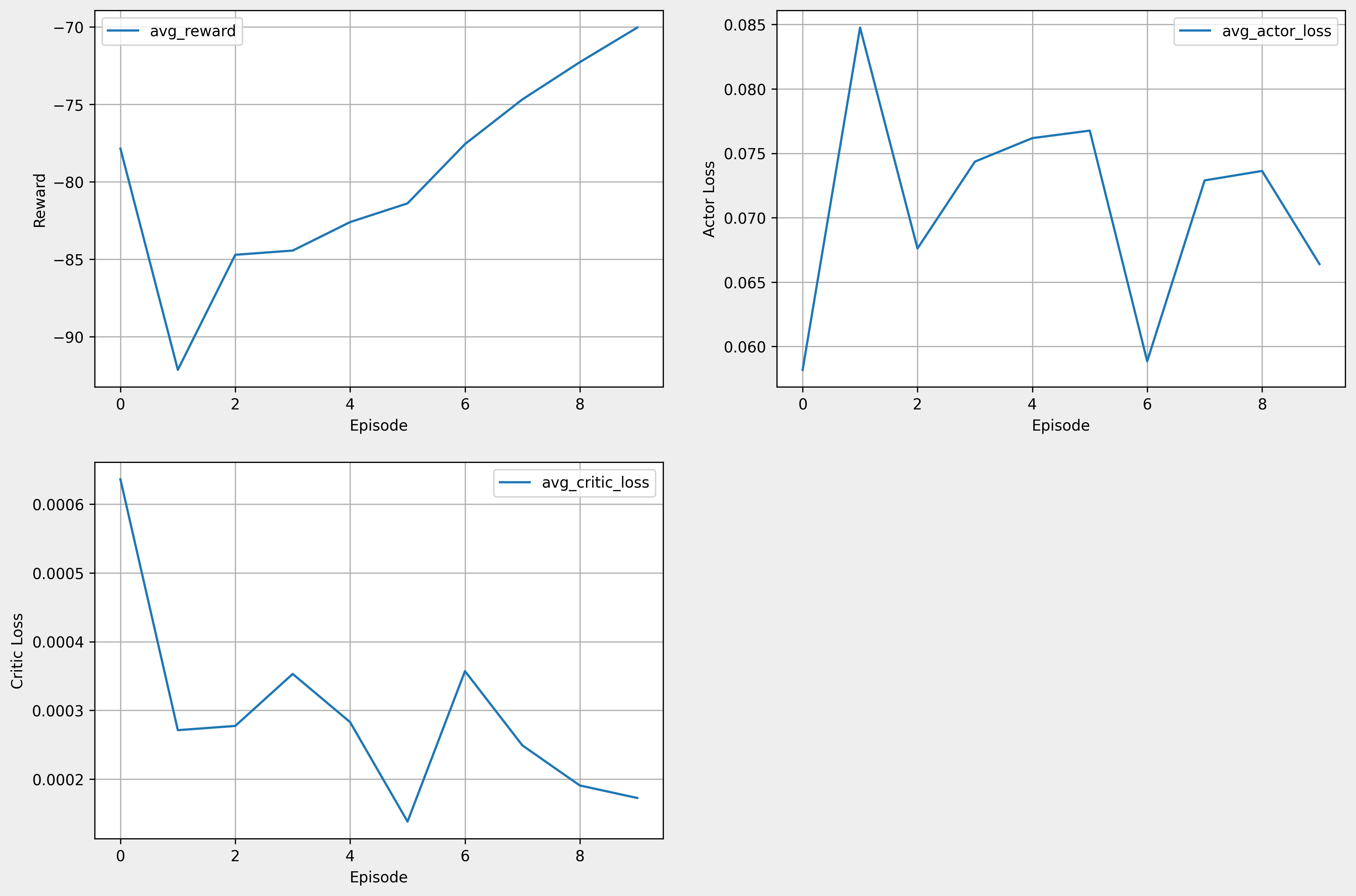
- critic learning rate 0.001 → 0.0001
- 첫 번째 episode에서 386번째 time step에서 goal에 도달함.
- 세 번째 episode에서 268번째 time step에서 goal에 도달함.
- 네 번째 episode에서 130번째 time step에서 goal에 도달함.
- 결과적으론 학습이 잘 되지 않음.
5. 추가 학습 진행
| episode | 50 |
|---|---|
| time step | 1000 |
| batch size | 256 |
| actor learning rate | 0.001 |
| critic learning rate | 0.001 |
| tau | 0.001 |
| buffer size | 1000000 |
| hideen size | 512 |
| 소요 시간(GPU 활용) | 3시간 24분 38초 |
reward_d = - distance_0 / 5
if distance_0 < 0.05 and step > 3:
self.get_logger().info('Goal Reached')
self.goal_0 = True
else:
self.goal_0 = False
if self.goal_0 is True: reward_0 = 20
return reward_d + reward_0
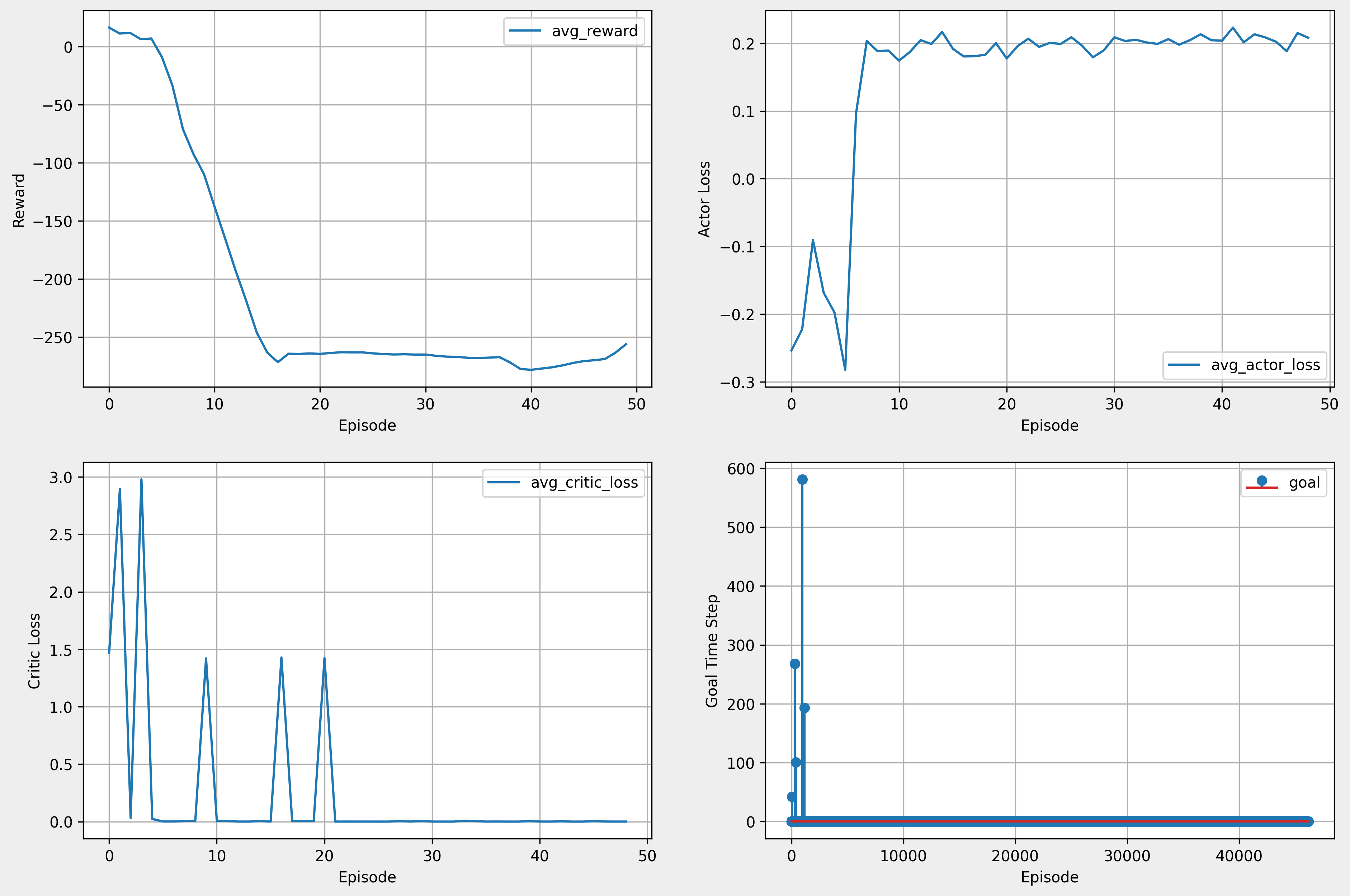
- 같은 환경에서 추가 학습 진행
- 학습이 잘 되지 않았다.
- ‘Goal Time Step’ 그래프는 어떤 time step에서 goal을 달성했는지 판단하기 위해 제작한 것이다. x축은 에피소드의 전체 time step이고, y축은 goal을 달성한 time step이다. 예를 들어 3번째 에피소드의 245번째 time step에서 goal에 달성하면, 해당 해피소드 time step에서 time step 수에 해당하는 점을 찍게 된다.
6. 에피소드의 최대 시뮬레이션 시간 설정 후 학습
| episode | 50 |
|---|---|
| time step | 200 |
| batch size | 256 |
| actor learning rate | 0.001 |
| critic learning rate | 0.001 |
| tau | 0.001 |
| buffer size | 1000000 |
| hideen size | 512 |
| 에피소드 최대 시뮬레이션 시간 | 20 |
| 소요 시간(GPU 활용) | 기록 측정 실수 |
reward_d = - distance_0 * 2
if distance_0 < 0.05 and step > 3:
self.get_logger().info('Goal Reached')
self.goal_0 = True
else:
self.goal_0 = False
if self.goal_0 is True: reward_0 = 20
return reward_d + reward_0
- 에피소드마다 최대 시뮬레이션 시간을 20초로 설정
- 20초 동안 약 180번의 time step 진행
- reward_d 함수 변경
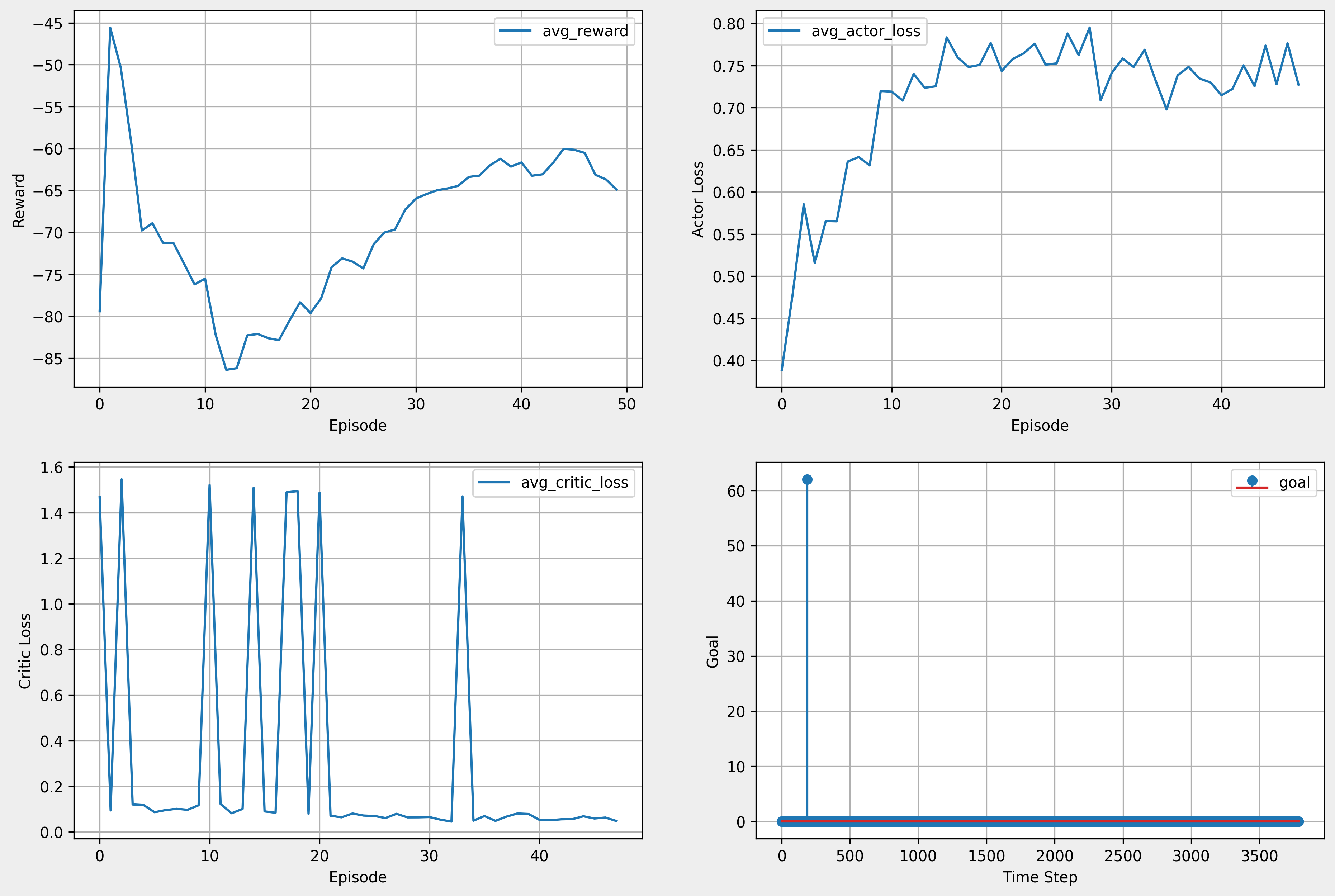
7. 하이퍼 파라미터 변경 후 학습
| episode | 50 |
|---|---|
| time step | 200 |
| batch size | 256 |
| actor learning rate | 0.0001 |
| critic learning rate | 0.0001 |
| tau | 0.001 |
| buffer size | 50000 |
| hideen size | 512 |
| 에피소드 최대 시뮬레이션 시간 | 20 |
| 소요 시간(GPU 활용) |
reward_d = - distance_0 / 5
if distance_0 < 0.05 and step > 3:
self.get_logger().info('Goal Reached')
self.goal_0 = True
else:
self.goal_0 = False
if self.goal_0 is True: reward_0 = 20
return reward_d + reward_0
- actor, critic lr 변경 0.001 → 0.0001
- buffer size 변겅 1000000 → 50000
- 학습 잘 안 됨.
8. 보상 함수 변경 후 학습
| episode | 20 |
|---|---|
| time step | 1000 |
| batch size | 256 |
| actor learning rate | 0.001 |
| critic learning rate | 0.001 |
| tau | 0.9999 |
| buffer size | 1000000 |
| hideen size | 512 |
| 소요 시간(GPU 활용) | 34분 55초 |
reward_d = - 0.1 * (distance_0**np.e)
if reward_d < -5: reward_d = -5
if distance_0 < 0.05 and step > 3:
self.get_logger().info('Goal Reached')
self.goal_0 = True
else:
self.goal_0 = False
if self.goal_0 is True: reward_0 = 100
return reward_d + reward_0
- rewrad_d 함수 변경
- 각도 예외 처리
if state[1] < -1.570795 or state[1] > 1.570795:
state[1] = random.uniform( -1.570795, 1.570795)
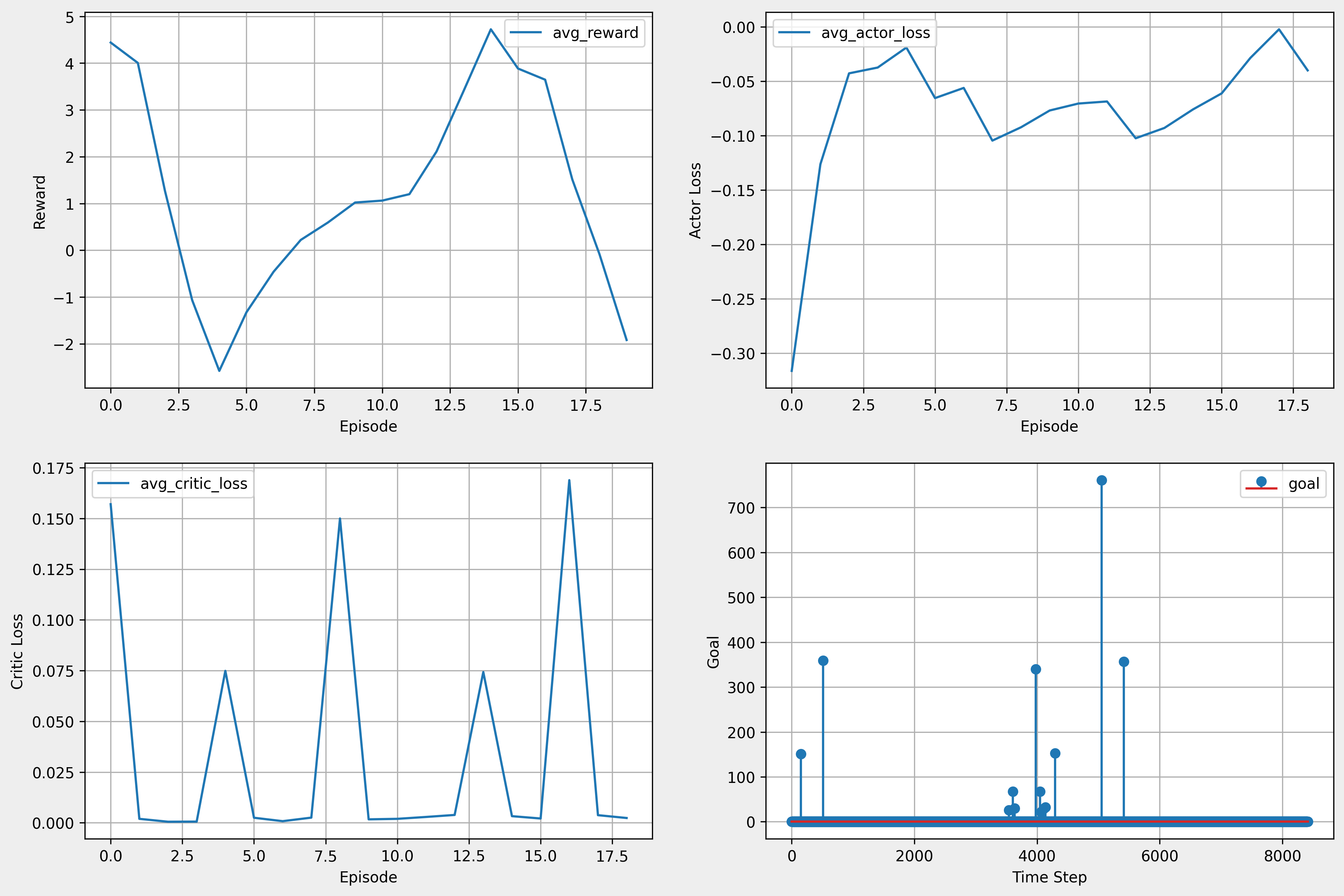
9. 추가 학습 진행
| episode | 80 |
|---|---|
| time step | 1000 |
| batch size | 256 |
| actor learning rate | 0.001 |
| critic learning rate | 0.001 |
| tau | 0.9999 |
| buffer size | 1000000 |
| hideen size | 512 |
| 소요 시간(GPU 활용) | 약 4시간 40분 |
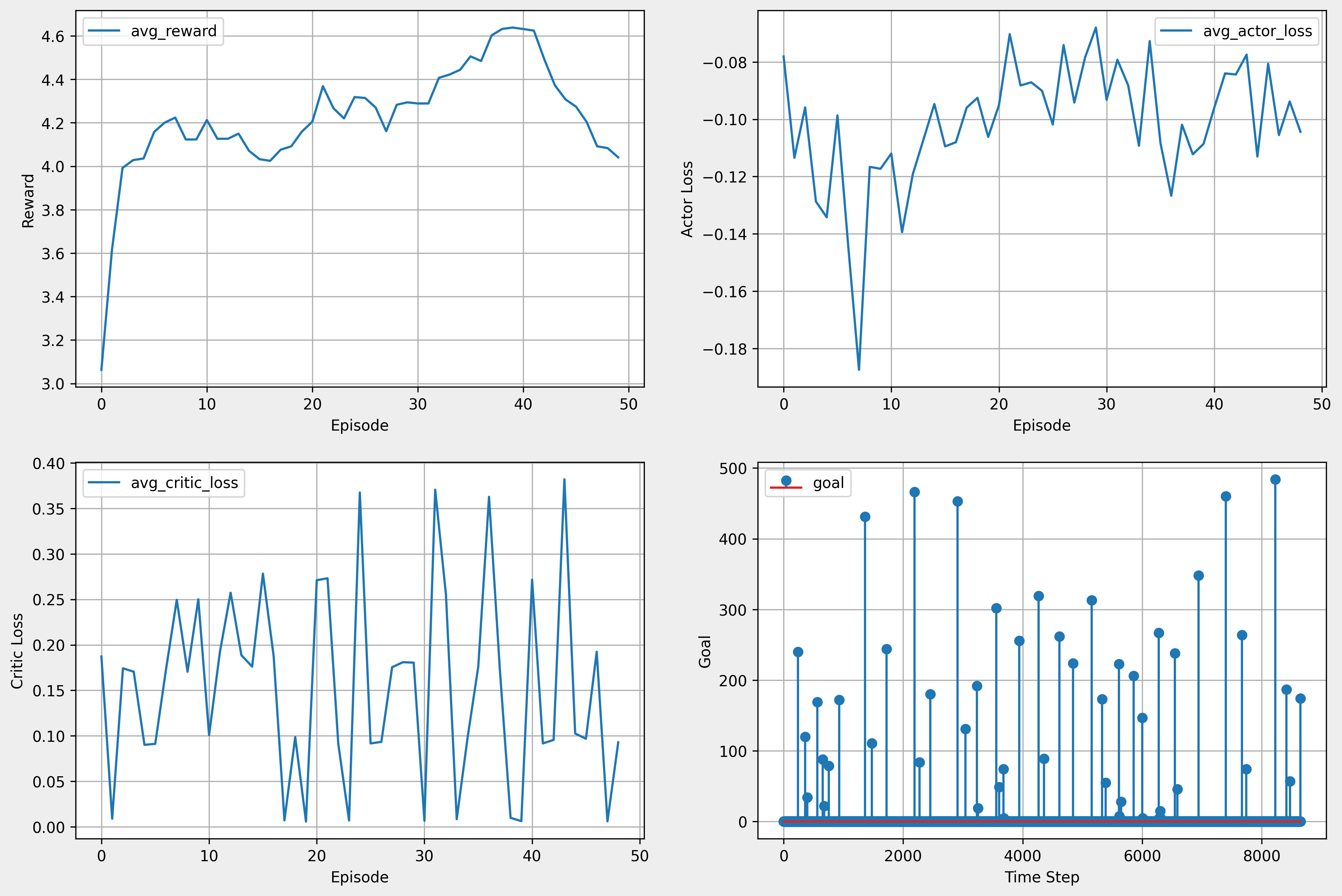
reward_d = - 0.1 * (distance_0**np.e)
if reward_d < -5: reward_d = -5
if distance_0 < 0.05 and step > 3:
self.get_logger().info('Goal Reached')
self.goal_0 = True
else:
self.goal_0 = False
if self.goal_0 is True: reward_0 = 100
return reward_d + reward_0
if state[1] < -1.570795 or state[1] > 1.570795:
state[1] = random.uniform( -1.570795, 1.570795)
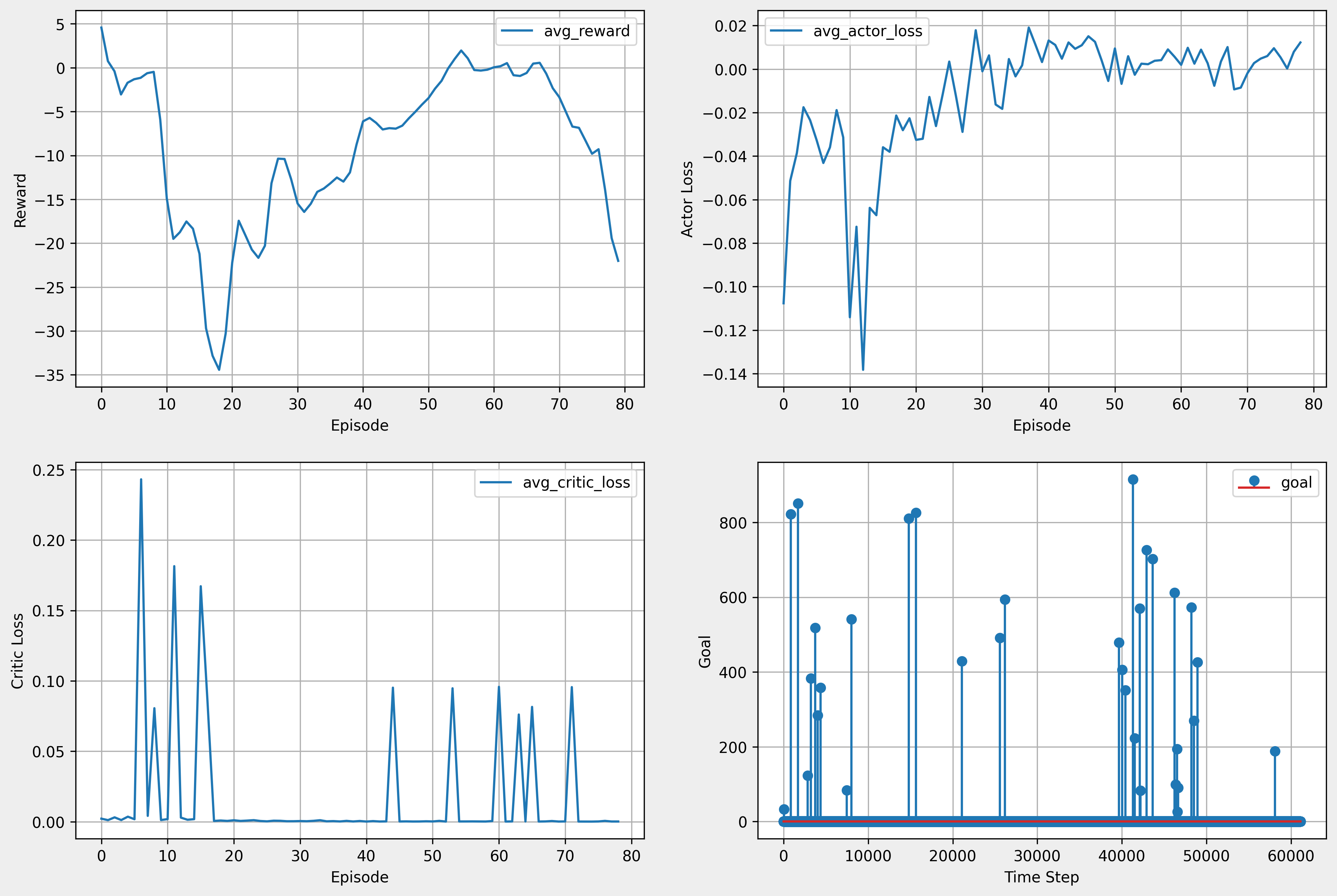
- 바로 위와 동일 조건에서 100 episode 더 학습
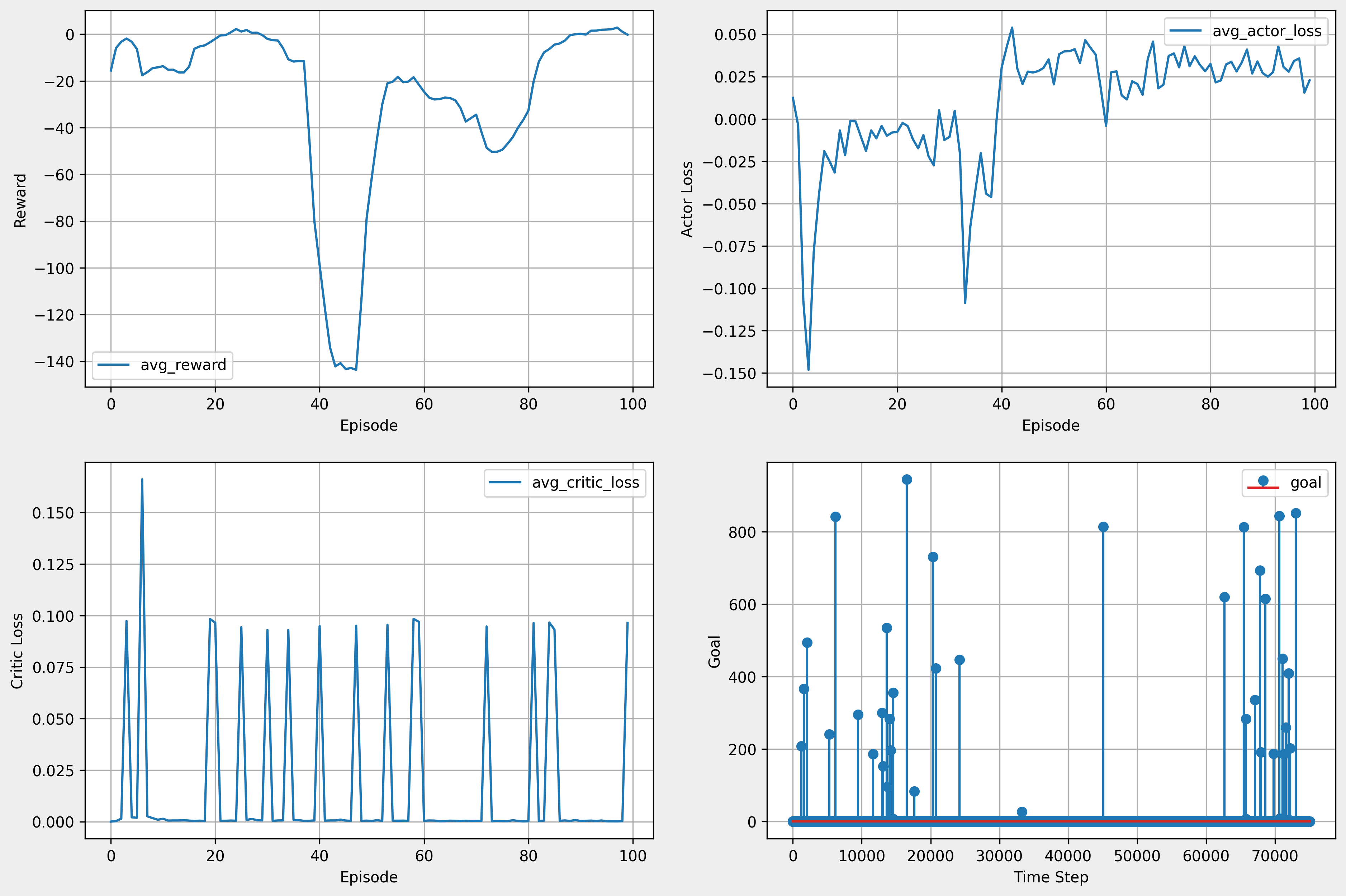
- lr 변경(0.001 → 0.0001) 후 100 episode 학습
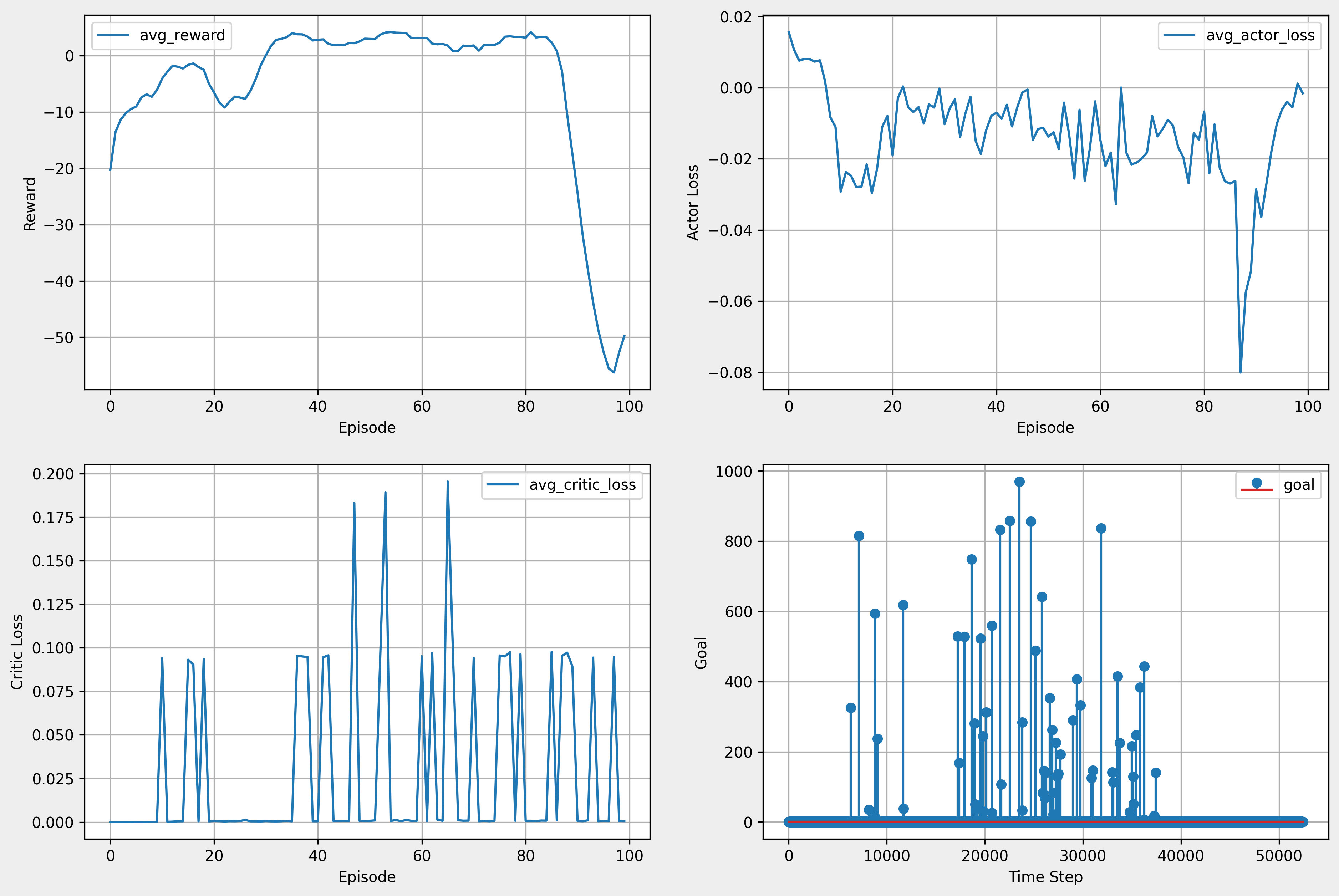
- 3시간 50분
10. 최종 학습 결과
- 마지막 학습 진행 결과
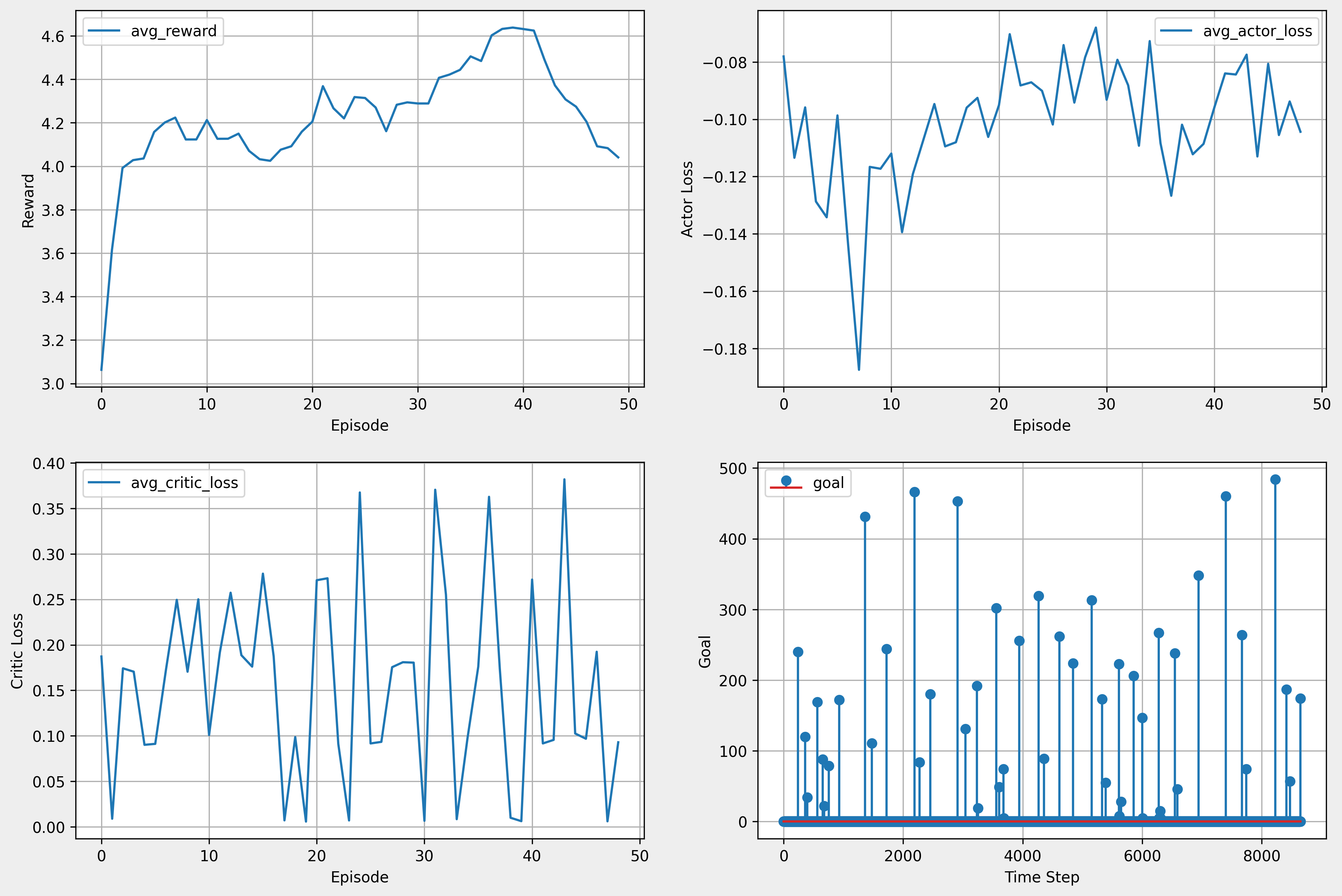
- 전체 학습 결과