[Project#0] 프로젝트 소개 - Trash Throwing Simulation with Deep Reinforcement Learning
1. 학술 소모임 ‘BARAM’
학술 소모임 ‘BARAM’에서는 매 학기 개인 작품을 진행한다. 서로 질문과 피드백을 진행하는 시간을 가지며 함께 성장하는 문화를 형성한다. 프로젝트 소개에서는 어떤 작품을 제작하며, 어떻게 구현할지에 대한 내용을 서술한다.
2. 작품 선정 동기
‘로봇은 단순노동에 활용하고 사람은 스스로 가치 있다고 생각하는 일을 위해 힘써야 한다’고 생각한다. 주변을 살펴보면 새벽에 쓰레기를 수거하고 계신 환경미화원분들을 쉽게 볼 수 있다. 쓰레기를 쉽고 빠르게 수거하기 위해 로봇팔을 활용한 ‘던지기’ 기능을 제시하고자 한다. 즉, 로봇팔과 심층강화학습 기술을 융합하여 쓰레기 던지기 로봇을 제작하고자 한다.

‘던지기’ 동작을 학습하기 위해 DDPG(Deep Deterministic Policy Gradient) 알고리즘을 활용한다. DDPG는 Model Free 알고리즘으로 환경을 정확히 인지하지 않아도 된다는 장점이 있다. 또한, 연속적인 환경에서 강화 학습을 가능하게 하는 알고리즘이다. 로봇팔의 움직임은 시간에 따라 변화하며, 연속적인 궤적을 생성한다. 그러므로 이산적인 환경이 아니라 연속적인 환경이라 볼 수 있다.
3. 프로젝트 시나리오
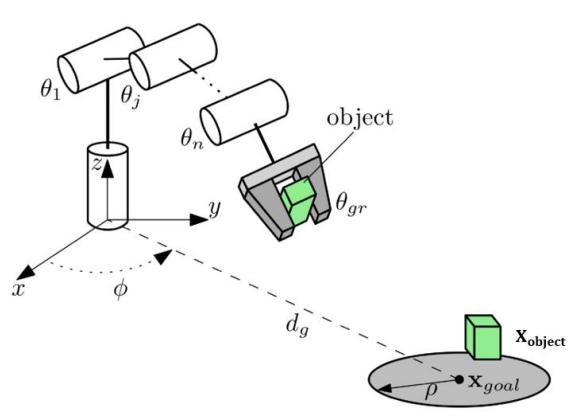
- Gazebo 환경에서 로봇팔, Object(쓰레기), 목표 지점(쓰레기통)을 초기 환경으로 설정한다.
- 무작위로 로봇팔이 Object(쓰레기)를 목표 지점(쓰레기통)을 던진다.
- DDPG(Deep Deterministic Policy Gradient) 알고리즘에 따라 학습을 진행한다.
- 학습하는 중간에 모델을 평가하여 ‘쓰레기통에 쓰레기 넣기’ 성공 확률을 측정한다.
- 성공 확률이 80% 이상이면 학습을 종료한다.
4. 프로젝트 목표
- 가상 학습 환경 구현
- DDPG(Deep Deterministic Policy Gradient) 구현
- 쓰레기 던지기 행동 학습
5. Architecture
5.1. Hardware Architecture
- Doosan Robotics의 A0912 모델을 활용한다.
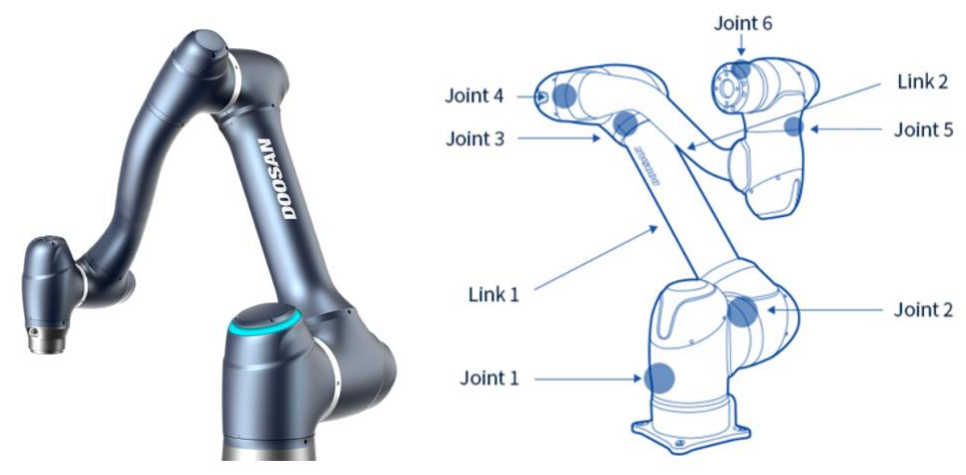
5.2. System Architecture
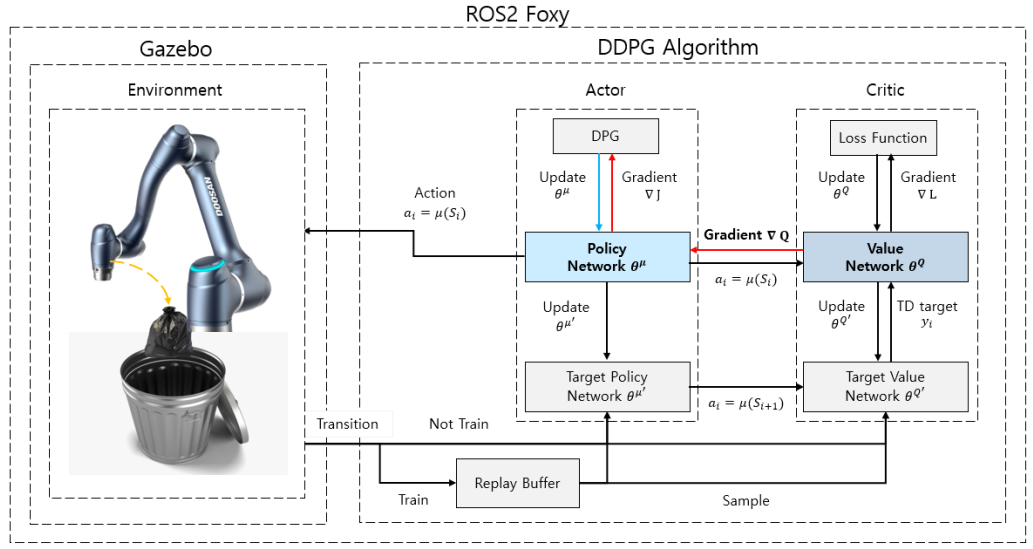
6. 프로젝트 구현 내용
6.1. 가상 학습 환경 구현

로봇팔은 하드웨어 아키텍쳐에서 언급한 두산 로보틱스의 A0912 모델을 사용한다. Object는 실제 쓰레기 형태를 구현하기에 어려움이 있을 거라 생각되어 구체를 활용한다. 목표 지점은 속이 빈 원기둥 모양을 선택하였다. 마지막으로 그리퍼는 Object를 잡기 위하여 집게 모양의 그리퍼를 선정하였다.
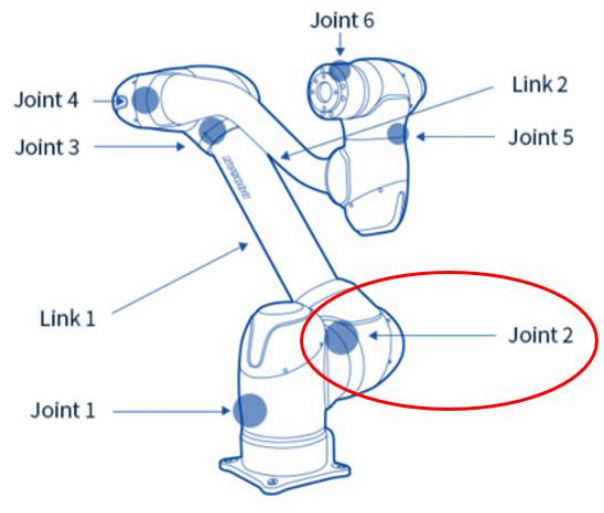
학습 시간을 위해 각 Joint를 0 ~ 180도로 각도를 제한한다. 단, Joint 1의 각도는 제한하지 않는다. 로봇을 기준으로 모든 방향에서 목표 지점(쓰레기통)이 생성 될 수 있기 때문이다.
6.2. DDPG(Deep Deterministic Policy Gradient) 구현
- DDPG 알고리즘의 목적은 목적 함수를 최대화 시키는 것이다.
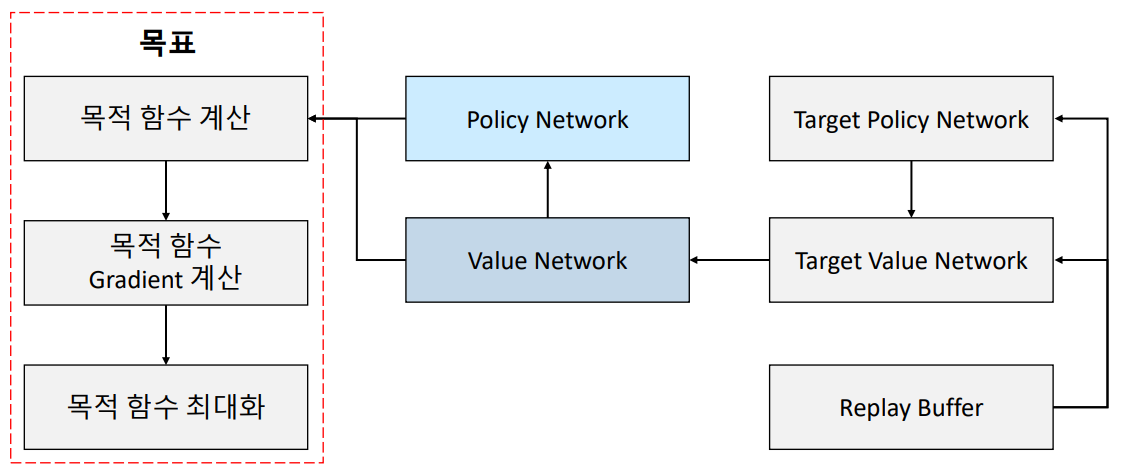
- 수식으로 설명하면, 목적 함수가 최대화 되는 $\theta^{\mu}$ 를 업데이트한다. 자세한 내용은 생략한다. 더 방대한 내용이 존재하지만 프로젝트를 제작해가며 차차 정리할 계획이다.

- Reward Function(보상 함수)
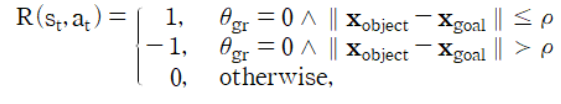
- $\theta_{gr}$: 그리퍼가 열리면 0, 닫히면 1을 의미한다.
- $X_{object} - X_{goal}$: Object(쓰레기)와 목표 지점(쓰레기통)의 거리를 계산한다.
-
Object(쓰레기)와 목표 지점(쓰레기통)이 가까워질수록 보상을 준다.
- Network 구조는 아래와 같다.
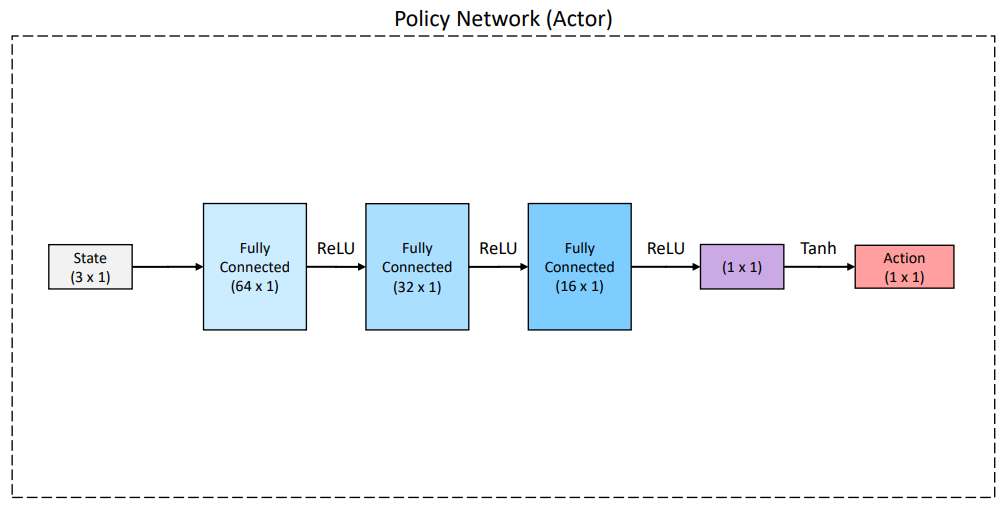
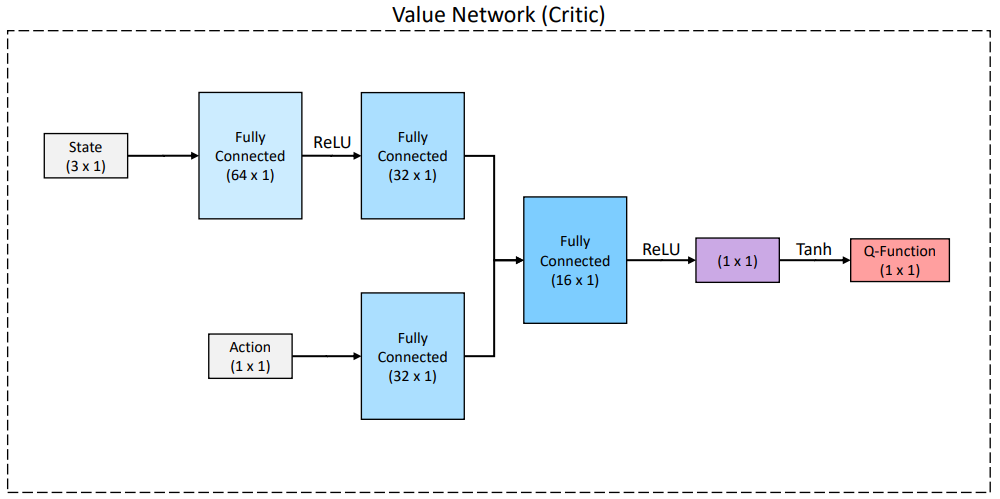
6.3. 학습 평가
- 한 에피소드 당 최대 step은 다음과 같다. ${시뮬레이션의 \ 최대 \ 시간 \over Sampling \ 시간} = {20 \over 0.05} = 400$
- 에피소드가 1000번 진행될 때마다 평가한다. 평가 시에는 학습 파라미터의 업데이트를 멈춘다. 500번을 던져서 성공 확률이 80% 이상일 때 학습을 종료한다.