Lecture 1: Introduction to Reinforcement Learning
1. 기계 학습 분류 (Branches of Machine Learning)
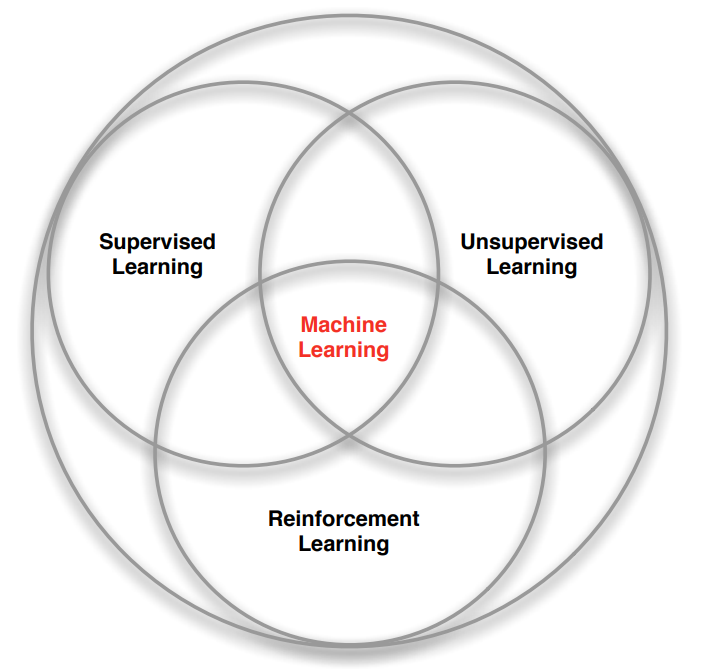
기계 학습(Machine Learning)은 지도 학습(Supervised Learning), 비지도 학습(Unsupervised Learning), 강화 학습(Reinforcement Learning) 3가지로 나뉜다. 지도 학습과 비지도 학습에 대한 내용은 자세히 다루지 않으며, 강화 학습과 다른 학습의 차이점은 아래와 같다.
-
감독관(Supervisor)가 없고, 보상 신호(reward signal)만 존재한다.
Supervisor란 정답을 알려주는 존재이다. 그래서 필자는 감독관 보다는 선생님이라는 표현이 맞는 것 같다. 즉, 강화 학습은 선생님이 존재하지 않는다. 옳바른 방향으로 이끌어줄 선생님이 없고, 스스로 경험한 후 옳바른 방향인지 나쁜 방향인지 보상 신호를 통해 방향을 찾아간다.
이미지를 활용한 지도 학습의 경우 학습할 때 어떤 이미지가 고양이이고, 개인지 정확히 구별(라벨링, labelling)되어 있다. 인공지능이 새로운 이미지를 입력 받았을 때 예측을 시도하고 틀렸을 때 그에 따라 수정한다. 그러나 강화 학습은 스스로 하는 행동에 대한 정답이 존재하지 않는다. 그저 옳바른 방향인지 나쁜 방향인지 알 수 있을 뿐이다. 강화 학습을 활용한 인공지능이 어느 쪽으로 향해야 하는지 판단하는 근거는 보상 신호이다.
-
피드백이 즉각적이지 않고 늦어질 수 있다.
어떤 행동을 했을 때 그 피드백, 보상이 10분 뒤에 전달될 수 있다. 10분 사이에 다양한 행동을 했다면 어떤 행동이 옳바른 방향으로 가는 것인지 구분하기 어렵다. 이것은 강화 학습에서 해결해야 할 문제 중 하나이다.
-
시간이 중요하다. 강화 학습의 데이터는 i.i.d 데이터가 아니라 sequential 데이터이다.
강화 학습의 데이터는 끊어진 데이터가 아니라 연결된 데이터라는 뜻이다.
-
에이전트(Agent)의 행동이 다음 데이터에 영향을 준다.
에이전트의 행동으로 인해 에이전트의 상태는 변화한다. 그래서 다음 데이터는 변화할 수밖에 없다. 특정 데이터를 어떤 식으로 다룰지 생각하는 것도 어려운 문제이다.
2. 용어 정리
2.1. 보상(Rewards)
2.1.1. 정의
Reward는 스칼라 피드백 신호이다. 벡터가 아니라 무조건 값 하나만을 보상으로 전해줘야 한다. Reward는 Agent가 t 번째 스텝에서 얼마나 잘 수행하고 있는지를 의미한다. Agent는 누적 보상(cumulative reward)을 최대화(Maximise)하는 것이 목적이다. 단 한 번의 Reward가 아니라 모든 스텝이 끝났을 때, 모든 Reward를 더한 것을 최대화 하는 것이 목적이다.
강화 학습은 보상 가설(Reward hypothesis)을 기본으로 한다. 보상 가설의 정의는 “All goals can be described by the maximisation of expected cumulative reward”이다. 직역하자면 “모든 목표는 예상 누적 보상의 최대화로 설명할 수 있습니다.”이다. 쉽게 말하자면, 한 순간의 reward를 최대화하는 것이 아닌 모든 순간의 reward의 합계를 최대화하는 것을 의미한다.
2.1.2. 순차적 의사결정(Sequential Decision Making)
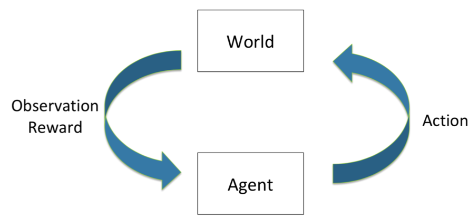
순차적 의사결정은 왼쪽 그림과 같이 Close Loop에서 World와 Agent가 상호작용하면서 연속적인 결정을 만들어 가는 것이다. 순차적 의사결정의 목적은 기대 보상을 극대화하기 위한 행동(Action)을 선택하는 것이다. 기대 보상이란 한 번의 보상이 아닌 모든 순간의 보상의 합산이다. ‘기대’라는 말을 붙인 이유는 모든 결정이 옳지만은 않기 때문이다. World는 예측하기 어렵기 때문에 Agent의 결정이 옳을 수도 옳지 않을 수도 있다. 중요한 것은 Agent의 행동은 “단기적인 보상”과 “장기적인 보상”을 고려해서 결정해야 한다는 것이다. 그래서 보다 장기적인 보상을 얻기 위해 즉각적인 보상을 희생하는 것이 더 나을 수 있다.
예를 들어, 바둑을 할 때 세 수 앞을 바라보고 착수하는 경우이다. 바로 앞의 수가 아닌 미래의 수를 염두해 두고 현재의 수를 착수해야 한다. 그래서 학습할 때 즉각적인 보상 뿐만 아니라 장기적인 보상이 존재해야 한다.
2.2. 에이전트(Agent)와 환경(Environment)
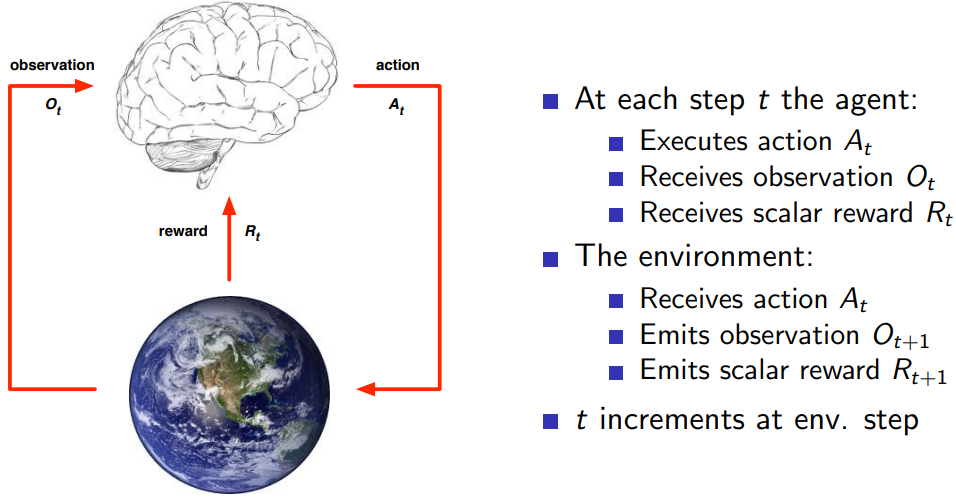
에이전트는 생각하고 행동(Action, 결정)하는 주체이며, 에이전트를 제외한 주변의 모든 것이 환경이다. 로봇이 길거리를 걷는 행위를 학습할 때, 로봇이 에이전트가 되고 로봇을 제외한 길거리 모든 것이 환경이다. 포트폴리오를 관리 감독하는 알고리즘을 학습할 때 알고리즘이 에이전트이며, 포트폴리오가 환경이 된다.
중요한 것은 타임스텝이 존재한다는 것이다. 한 스텝마다 에이전트는 행동을 환경에게 줘야 하고, 환경은 observation과 reward를 에이전트에게 전달해야 한다.
2.3. 관찰(Observation)
강화 학습에서 observation은 에이전트가 환경과 상호작용하면서 받는 입력 데이터를 의미한다. 이러한 입력 데이터는 주로 센서에서 수집되는 정보로, 이 정보를 기반으로 에이전트는 현재 상태를 파악하고 적절한 행동을 결정한다. 일반적으로 벡터, 이미지, 음향 등의 형태로 표현되며, 로봇이 주행하는 환경에서 observation은 센서에서 수집한 거리, 속도, 방향, 이미지 등의 데이터를 포함할 수 있다. 따라서, observation은 강화 학습에서 에이전트가 상태를 파악하는 데 매우 중요한 역할을 한다.
2.4. 기록(History)
\[H_t = O_1, R_1, A_1, ..., A_{t-1}, O_t, R_t\]History는 Observation, Reward, Action의 연속이다. History는 많이 활용되는 내용은 아니다. 그저 이런 개념을 갖고 있다~ 정도만 알면 될 듯하다.
History를 보며 깨닫게 된 것은 Observation과 Reward 보다 Action이 먼저 동작한다는 것이다. Action은 t-1까지 Observation과 Reward는 t까지 나타낸다. 즉, Action은 다른 것보다 한 번 적게 나타나는데 에이전트가 행동하고, 환경이 이를 받아 되돌려준음을 의미하는 것 같다.
2.5. 상태(State)
\[S_t = f(H_t)\]State는 무언가를 하기 정할 때 사용되는 정보이다. 에이전트의 State가 있을 수 있고, 환경의 State가 있을 수 있다. 각각의 State는 다른 것이다. State의 개념만 생각하면, 다음 수를 생각할 때 활용되는 정보를 의미한다. 에이전트를 예로 들면, 다음 행동을 선택하기 위해 이전까지의 History를 활용하는 것이다. 즉, State는 History의 함수이다. 모든 과거를 확인해서 State를 정의할 수도 있고, 일부분만 활용할 수도 있다. 모든 과거를 보는 것은 비효율적일 수 있다. 그만큼 정보량이 많아지기 때문이다.
2.5.1. 환경의 상태(Environment State)
환경의 상태는 $S_t^e$로 나타내며, 환경이 다음 Observaion과 Reward를 계산하기 위해 사용되는 데이터이다. $S_t^e$는 일반적으로 에이전트에게 알려주지 않는다. 알려지더라도 에이전트에게 관련 없는 정보일 수 있다.
2.5.2. 에이전트의 상태(Agent State)
\[S_t^a = f(H_t)\]에이전트의 상태는 $S_t^a$로 나타내며, 에이전트가 다음 Action을 계산하기 위해 사용되는 정보이다. $S_t^a$는 강화 학습 알고리즘에 사용되는 정보이며, History의 함수라고 생각하면 된다. 에이전트의 상태를 정의하기 위해 이전의 Observation, Reward, Action을 참고한다.
2.5.3. 상태의 예시(State Example)
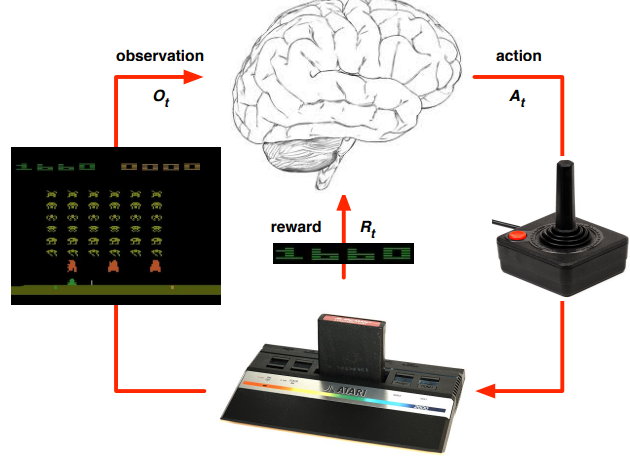
State의 개념만 본다면 이해가 되지 않을 것이다. 필자 또한 그랬으며, 직접 예시를 보고 State가 무엇인지 와닿았다. 우선, Environment State를 생각해보자. 환경의 상태는 무엇일까. 왼쪽 그림에서 보았을 때 Atari 게임팩을 의미한다. 조이스틱과 같은 게임기로부터 Action을 받으면 Atari 게임팩은 다음 화면(Observation)과 점수(Reward)를 보여준다. 게임팩 내부에서는 “나의 위치, 상대의 위치, 맵의 형태” 등 다양한 정보를 갖고 있을 것이며, Action에 따라 이들이 변화할 것이다. 게임팩 내부의 모든 정보가 Environment State가 될 수 있다.
Agent State는 무엇일까. 그림에서는 두뇌에 해당 된다. 게임 정보(Observation)와 점수(Reward)를 받고 다음 조작(Action)을 선택할 때 활용되는 데이터를 의미하며, 여기서 강화 학습 알고리즘이 분류된다.
2.5.4. Imformation State(a.k.a. Markov State, Markov Property)
Markov State의 개념은 “The future is independent of the past given the present”이다. 직역하자면, 미래는 현재를 고려할 때 과거와 무관하다. 즉, 미래는 현재만을 사용하면 된다는 것이다. 과거의 모든 정보는 상관없고 현재의 정보만으로 미래를 선택할 수 있을 때 이를 Markov 하다고 한다. 예를 들어, 헬리콥터를 운전할 때 현재의 위치, 기울어진 정도, 각속도, 바람의 방향, 바람의 세기가 주어졌을 때 핸들을 어느 정도 조종해야 하는지 알 수 있다. 과거의 모든 정보를 확인하지 않고 직전의 상황만 인식한 것으로도 미래를 예측할 수 있다. 이런 상황을 Markov 하다고 말할 수 있다.
반대로, 모든 정보를 모르고 바람의 방향만 주어졌다고 했을 때 우리는 어떻게 핸들을 조종할지 모를 수 있다. 그럴 경우 과거의 다양한 정보를 파악하여 어떤 식으로 조종할지 선택할 수 있을 것이다. 이런 경우 Markov 하지 않다고 이야기할 수 있다.
마르코프하다고 이야기할 수 있는 경우가 정보량의 차이는 아니다. 수학적인 의미를 살펴보자. 오른쪽 수식에서 첫 번째 줄은 Markov State의 정의이다. $S_{t+1}$의 확률은 $S_{t}$만 주어지든, $S_1$부터 $S_t$까지 주어지든 같다는 것이다.
두 번째 줄도 같은 의미이다. t까지의 History를 알고 있다면 t의 State를 계산할 수 있고, 앞으로의 History를 알 수 있다는 의미이기도 하다. 다시 말해, 상태는 미래에 대한 충분한 통계이다.
\[\mathbb{P}[S_{t+1} \mid S_t] = \mathbb{P}[S_{t+1} \mid S_1, ..., S_t]\\H_{1:t} \to S_t \to H_{t_1:\infty}\]그래서 Environment State $S_t^e$와 History $H_t$는 Markov 하다. 강화 학습에서 환경의 상태와 기록이 Markov 하지 않는 경우는 잘 다루지 않는다.
2.5.5. Agent State 설정의 중요성
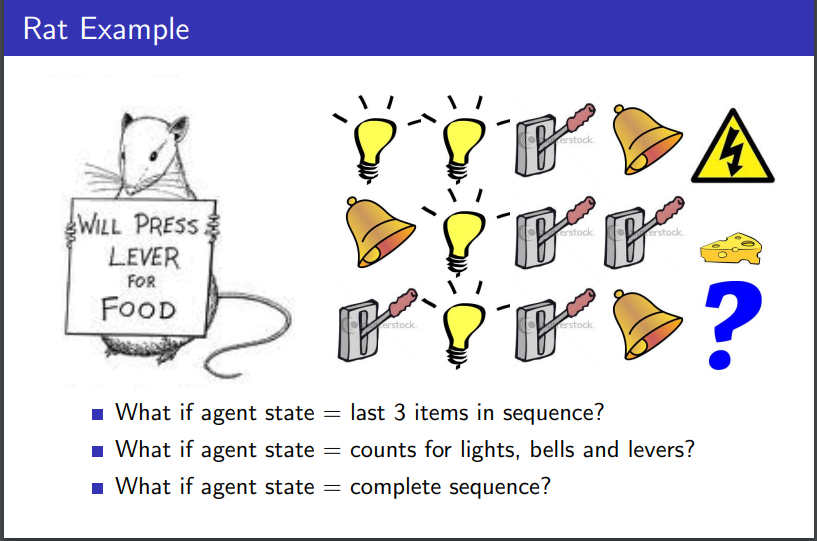
어느 쥐가 있고, 3개의 신호를 선택할 수 있다고 해보자. 첫 번째는 전구 켜기, 두 번째는 종 울리기, 세 번재는 레버 당기기이다. 그림에서 첫 번째 줄만 봐보자. 전구를 2번 켜고, 레버를 당긴 후 종을 울리니 전기 충격을 당했다. 두 번째 줄을 보면, 종을 울리고 전구를 켜고 레버를 두 번 당겼더니 치즈를 받았다. 그렇다면, 마지막 줄의 행동을 하면 무엇을 받게 될까?
-
마지막 3개의 행동을 Agent State로 선택했을 경우
첫 번째 줄은 (전구 켜기, 레버 당기기, 종 울리기)가 Agent State일 것이다. 두 번째 줄은 (전구 켜기, 레버 당기기, 레버 당기기)가 Agent State가 될 것이다. 마지막 줄은 첫 번째 줄과 Agent State가 같기 때문에 전기 충격을 받게 될 것이라 생각할 수 있다.
-
각 행동의 개수를 Agent State로 선택했을 경우
첫 번째 줄은 (전구 2개, 레버 1개, 종 1개)가 Agent State일 것이다. 두 번째 줄은 (전구 1개, 레버 2개, 종 1개)가 Agent State가 될 것이며, 마지막 줄은 (전구 1개, 레버 2개, 종 1개)일 것이다. 즉, 두 번재 줄과 마지막 줄의 Agent State가 같기 때문에 치즈를 받을 것이라 예측할 수 있다.
-
모든 sequence를 Agent State로 선택했을 경우
모든 Sequence를 Agent State로 설정하게 되면 마지막 줄에 무엇을 받을지 알 수 없다. 더 다양한 경우를 확인해야 한다.
2.6. Observable Environments
2.6.1. Fully Observable Environments
에이전트가 환경의 상태를 볼 수 있는 경우를 말한다. Fully Observable Environments의 경우 Observation, Agent State, Environment State가 모두 같다.
일반적으로 Markov decision process (MDP)라고 한다. 대부분의 강화학습을 MDP에서 다룬다.
\[O_t = S_t^a = S_t^e\]2.6.2. Partially Observable Environments
에이전트가 환경의 상태를 부분적으로 볼 수 있는 경우를 말한다. 로봇이 비전을 활용하여 움직이는 경우가 대표적인 예시이다. 카메라만 활용하여 주변 환경을 인식하면, 로봇의 절대적인 위치를 파악할 수 없다.
Parially Observable Environments의 경우 Agent State와 Environment State가 같지 않다.
일반적으로 partially observable Markov decision process (POMDP)라고 한다. POMDP의 경우 에이전트가 자체적으로 Agent State를 표현해야 한다. 이런 경우 다양한 방법이 있고 대표적으로 History를 선택한다든가, Beliefs of environment state나 RNN을 선택하기도 한다.
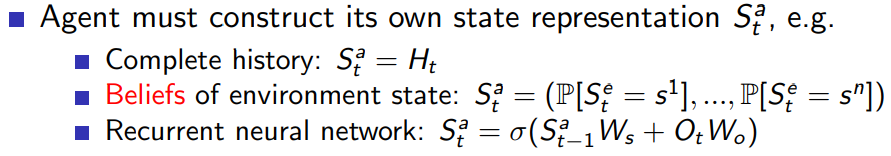
2.7. 정책(Policy)
Policy는 에이전트의 동작이다. 즉, 에이전트에게 State를 주었을 때 Action을 반환하는 함수이다. Policy는 2가지 종류가 있다. 바로 반환한는 함수과 확률적으로 반환하는 함수이다.
- Deterministic policy: $a = \pi(s)$
- Stochastic policy: $\pi(a \mid s) = \mathbb{P}[A_{t} = a \mid S_t = s]$
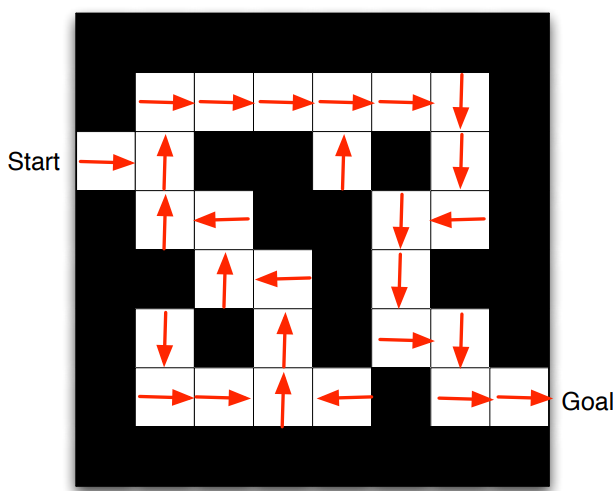
오른쪽 그림에서 보면, 각 위치에서의 화살표 방향이 Policy라 부를 수 있다.
2.8. 가치 함수(Value Function)
가치 함수는 미래 Reward에 대한 예측이다. State가 좋고 나쁨을 판단하는데 활용한다. 가치 함수에 아래 첨자로 $\pi$가 있다. Agent가 어떤 Poliy($\pi$)를 따라서 게임이 종료될 때까지 행동했을 때 얻을 수 있는 Reward의 총 기댓값이 가치 함수임을 의미한다. Policy 없이 Value Function이 정의될 수 없다는 말이기도 하다. 가치 함수가 기댓값인 이유는 행동을 선택함에 있어 확률이 존재하기 때문이다. Policy가 Stochastic Policy라면, 그 자체로도 확률이 존재한다. 그렇다면, Deterministic Polic y는 어떨까? Deterministic Policy는 확률 없이 인풋이 들어오면 아웃풋을 반환한다. 그래서 행동을 선택하는데 확률이 존재하지 않는다고 생각할 수 있다. 그러나 Deterministic Policy라도 Environment에서 확률이 존재한다. 예를 들어, 로봇이 걷고 있을 때 바람이나 중력의 영향으로 넘어질 수 있고, 울퉁불퉁한 지면으로 인해 기울어질 수 있다. 이로 인해 State가 변화하게 된다. 즉, Deterministic Policy라 하더라도 환경에 의해 State가 변화하는 확률이 존재한다.
\[V_{\pi}(s) = \mathbb{E_\pi} [R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + ... \mid S_t = s]\]
최적의 Policy를 따라 Value Function을 표현한 그림
2.9. Model
모델은 에이전트가 환경이 어떻게 될지 예측하는 것이다. Model은 다음 State와 다음 Reward를 예측할 수 있어야 한다.
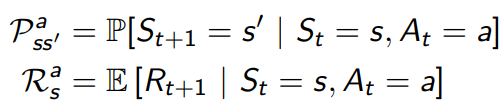
그림을 보면 모델이 무엇인지 알 수 있을 것이다. 모델은 에이전트가 환경이 어떻게 될지 예측하는 것이며, 다음 State와 Reward를 예측해야 한다. 미로 찾기 예시에서는 그리드 맵 전체가 모델($\mathcal{P_{ss’}^a}$)이며, 각 state에서의 숫자가 Reward($\mathcal{P_{s}^a}$)이다. 그림에서 아래 부분의 영역은 사라진 것을 확인할 수 있다. 이것은 모델이 완벽하지 않음을 의미한다.

2.10. Exploration and Exploitation
강화 학습은 스스로 다양한 수를 경험하며, 최적의 Policy를 찾는 학습 방법이다.
- Exploration: 환경에 대한 더 많은 정보를 찾는 것으로, 미개척지를 탐험하는 것이다.
- Exploitation: 알려진 정보를 이용하여 보상을 극대화하는 것으로, 현재 State에서 최고 Reward를 주는 Action을 선택하는 것이다.
탐색하는 것뿐만 아니라 탐색하는 것도 중요하다. 갔던 길로만 가면 그것이 진짜 최적의 길인지 알 수 없고, 새로운 길로만 가면 비효율적으로 학습할 것이다. 그래서 둘은 trade-off 관계이다.
2.11. Prediction and Control
- Prediction
- 정의: Policy가 주어졌을 때 미래를 평가하는 것.
- Prediction 문제를 푼다 == Value Function을 학습 시킨다.
- Control
- 정의: 미래를 최적화하는 것.
- Control 문제를 푼다 == 최적의 Policy를 찾는 것.
- $_*$ 의미
- 문자 아래에 $_*$ 이 있다면, optimal에 대한 내용이다.
- e.g. $v_*$
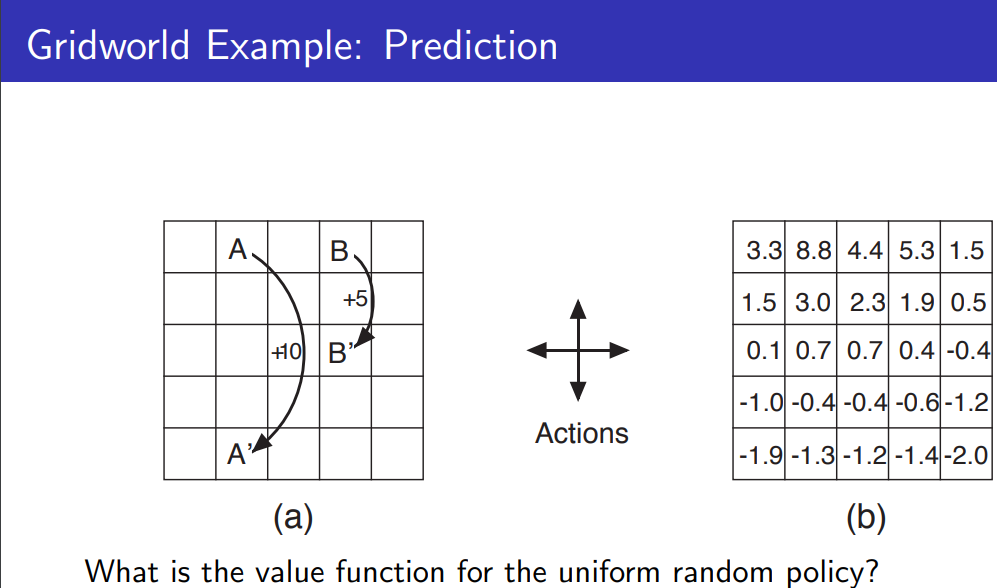

3. RL의 분류
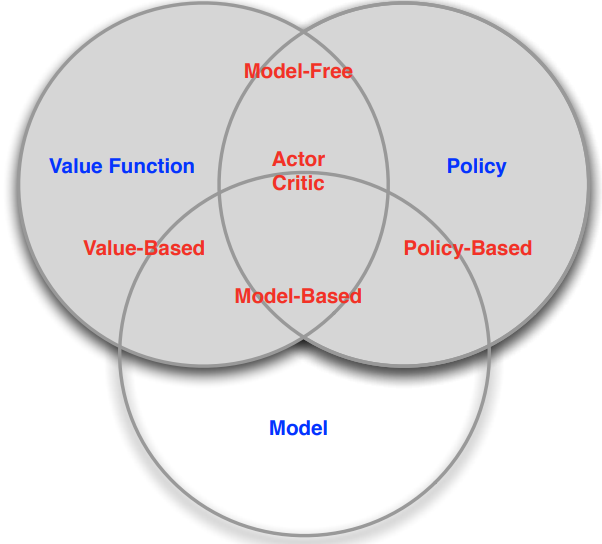
3.1. Value Function / Policy
- Value Based - Value Function만 있음
- No Policy (Implicit)
- Value Function
- Policy Based - Policy만 있음
- Policy
- No Value Function
- Actor Critic - Value Function, Policy 둘 다 있음
- Policy
- Value Function
3.2. Model
- Model Free - Model이 없음.
- Policy and/or Value Function
- No Model
- Model Based
- Policy and/or Value Function
- Model
3.3. Learning and Planning
- Reinforcement Learning
- 처음에 환경을 알 수 없음. → Model Free
- 에이전트가 환경과 상호작용하며 학습하며, Policy를 개선함.
- Planning
- 처음에 환경을 알고 있음. → Model Based
- 에이전트는 모델을 사용하여 계산을 수행합니다. 중요한 것은 외부 상호 작용 없이 계산한다는 것이다.
- 모델을 통해 계산하며, Policy를 개선함.
- a.k.a. search, deliberation, reasoning, introspection, pondering, thought
- e.g. tree search